
{kind=link}
Retrieval-Augmented Generation (RAG) transforms your pretrained LLM into a citation-powered knowledge engine by connecting it to external data sources. This step-by-step integration guide covers chunking strategies, vector databases, semantic search optimization, and enterprise security, delivering accurate, traceable AI responses without hallucinations.
You’re building an AI customer support bot, but your LLM keeps confidently making up product details that don’t exist. Sound familiar? That’s where RAG becomes your secret weapon.
I’ve helped dozens of SaaS teams solve this exact problem. RAG doesn’t just reduce hallucinations, it transforms your AI from a creative storyteller into a reliable knowledge worker that cites its sources.
Explore real-world deployment examples with our real-time RAG roadmap for SaaS products.
What is RAG + LLM, and Why Your App Needs It
RAG connects large language models to your knowledge bases, enabling real-time information retrieval with source citations. Unlike fine-tuning, RAG keeps data fresh and provides explainable AI responses through semantic similarity matching.
Think of RAG as giving your LLM a research assistant. When users ask questions, the system first searches your documents, finds relevant passages, and then feeds those to your LLM with instructions to answer based only on the retrieved information.
The magic happens through semantic search; your system understands that “How do I reset my password?” relates to documents about account recovery, even if they don’t use identical words.
Key benefits:
- Fresh data: Update documents without retraining models
- Citation transparency: Users see exactly where answers come from
- Cost efficiency: No expensive fine-tuning for domain knowledge
- Reduced hallucinations: Grounded responses from your actual data
Related reading: LLM Integration Guide | Setup Steps
RAG vs. Fine-Tuning vs. Long-Context: Choosing Your Strategy
RAG excels in dynamic knowledge bases that require explainability, while fine-tuning handles style adaptation and long-context works for stable, small datasets. Most enterprise applications benefit from RAG’s flexibility and citation capabilities.
| Approach | Best For | Pros | Cons |
|---|---|---|---|
| RAG | Dynamic docs, compliance | Fresh data, citations, and explainable | Infrastructure complexity |
| Fine-tuning | Custom tone, specialized skills | Model personalization | Ongoing training costs |
| Long-context | Small, static knowledge sets | Simple architecture | Token costs, context drift |
Here’s my take: Start with RAG if your knowledge changes monthly or you need to explain AI decisions to stakeholders. Fine-tune only after RAG proves your use case works.
Learn more: LLM Support
Step-by-Step RAG Implementation Without Over-Engineering
Successful RAG follows eight core steps: ingest documents, chunk content, generate embeddings, store vectors, retrieve by similarity, optionally rerank, prompt with context, and evaluate outputs. Begin with five simple 0-token chunks and basic similarity search.
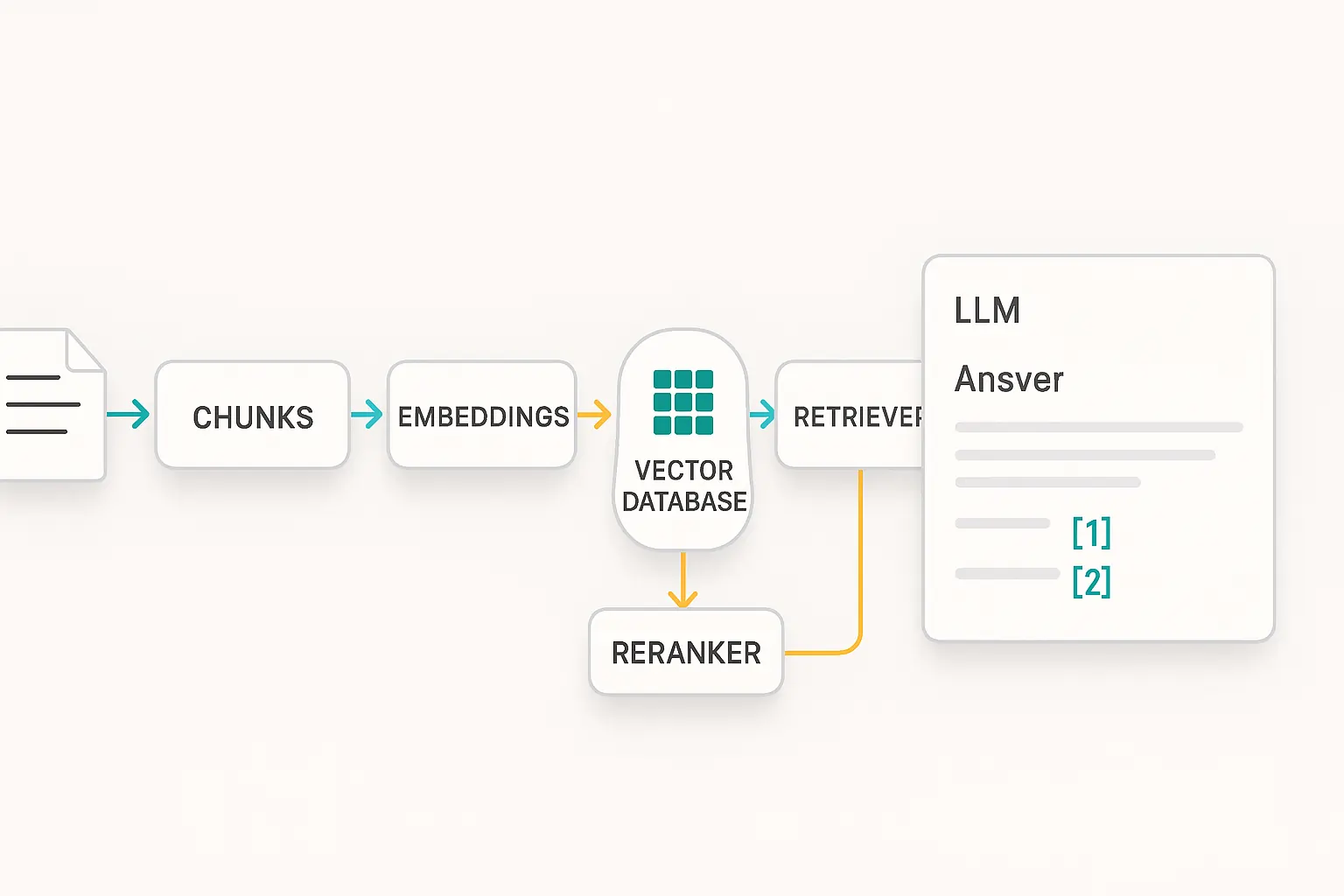
The RAG Pipeline:
- Ingest external data sources
Import PDFs, HTML, Markdown, databases, or API responses into your system. - Chunk documents intelligently
Split content into 500-800 token passages with 10-20% overlap to preserve context. - Generate embeddings
Use models liketext-embedding-3-largeor open-source alternatives (e5, bge) to convert text into vectors. - Store in a vector database
Choose from pgvector (cost-effective), Pinecone (managed), Weaviate (hybrid search), or Milvus (scalable). - Retrieve by semantic similarity.
Find the top-k most relevant chunks using cosine similarity plus metadata filters. - Optional: Rerank for precision
Apply MMR (Maximum Marginal Relevance) or cross-encoders to improve result quality. - Generate with citations
Prompt your LLM to answer based on retrieved passages and cite sources. - Evaluate and iterate
Track faithfulness, groundedness, and relevance metrics through automated testing.
Pro tip: I always recommend starting with a basic similarity search before adding reranking. Most teams over-engineer their first RAG system.
Managed vs. Open-Source: Picking Your Stack
Managed RAG services, such as Vertex AI RAG Engine or AWS Bedrock, accelerate time-to-value but limit customization options. Open-source stacks using LangChain, along with PostgreSQL vector, offer control at the cost of increased operational overhead.
Managed Solutions (Fast Path):
- Google Vertex AI RAG Engine: Built-in reranking, enterprise security
- AWS Bedrock + Amazon Kendra: Native retrieval integration
- Microsoft Azure AI Foundry: Comprehensive evaluation tools
Open-Source Control:
- LangChain/LlamaIndex: Orchestration frameworks with extensive integrations
- pgvector: PostgreSQL extension for cost-effective vector storage
- Weaviate/Milvus: Purpose-built vector databases with hybrid search
Decision framework:
- Tight deadline? → Managed platform
- Strict compliance requirements? → Evaluate VPC/data residency options
- Budget constraints? → Open-source with minimal ops

According to recent Stack Overflow discussions, teams frequently struggle with ChromaDB performance, and LlamaIndex merging managed solutions help alleviate these headaches.
Explore: Integration Tools Comparison
Ensuring Accuracy and Enterprise Security
Enterprise RAG requires automated evaluation pipelines that measure faithfulness and groundedness, as well as ACL-aware retrieval that respects user permissions. Implement CI/CD gates that fail deployments when quality metrics decline.
Evaluation Strategy:
- Build golden datasets: Curated question-answer pairs with expected sources
- Track key metrics: Faithfulness (answer matches sources), groundedness (claims supported), relevance (retrieved docs help)
- Automate quality gates: Fail builds when metrics drop below thresholds
- Human oversight: Review edge cases and model behavior
Security Essentials:
- Access control integration: Filter retrieved documents by user roles/tenants
- PII detection and redaction: Scrub sensitive information before LLM processing
- Prompt injection defenses: Validate and sanitize user inputs
- Audit logging: Track all queries and retrieved documents
Strengthen your defenses further with proven RAG security best practices covering GDPR, SOC 2, and risk control frameworks.
Real-world example: A fintech client required different document access levels for advisors and clients. We implemented metadata tagging during ingestion, then filtered retrieval by user JWT claim, maintaining security without sacrificing performance.
Performance Optimization and Cost Management
RAG latency typically breaks down into three components: retrieve (50-100ms), rerank (100-200ms), and generate (1-3s for streaming). Aggressive caching of frequent queries and embedding reuse can reduce costs by 60-70%.
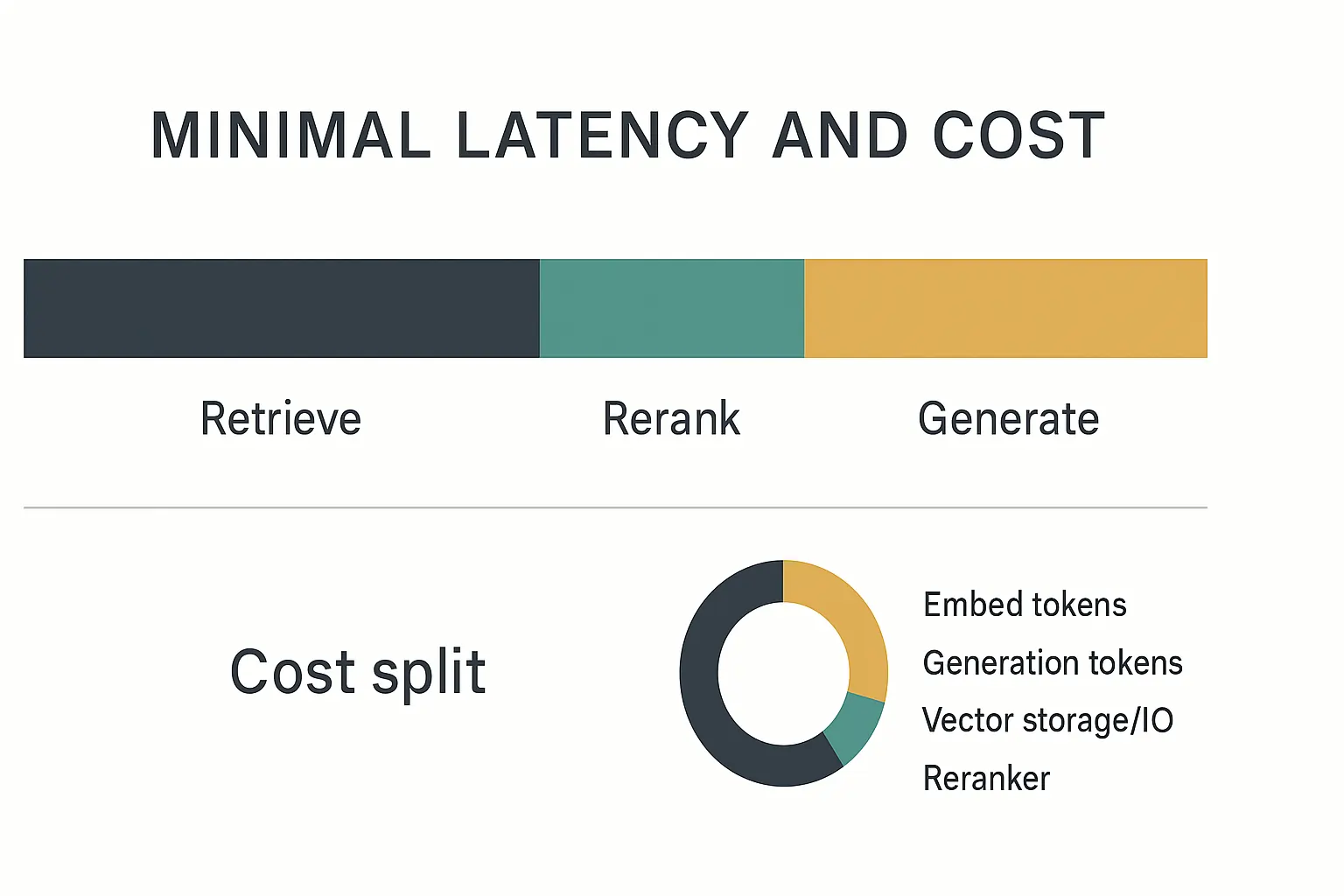
Latency Budget:
- Embedding lookup: ~50ms for small corpora
- Vector similarity search: 50-100ms depending on index size
- Reranking: 100-200ms with cross-encoders
- LLM generation: 1-3 seconds (streaming improves perceived speed)
Cost Optimization:
- Embedding costs: $0.13 per 1M tokens (OpenAI text-embedding-3-large)
- LLM generation: $15-60 per 1M tokens, depending on model
- Vector storage: $0.70-2.00 per GB/month (managed services)
- Caching impact: 60-70% cost reduction for repeated queries
Optimization techniques:
- Cache embeddings for frequently accessed documents
- Use semantic caching for similar questions
- Implement tiered reranking (expensive models for top candidates only)
- Monitor token usage with automatic truncation guards
According to NVIDIA’s RAG analysis, proper caching strategies typically reduce production costs by 65%.
Advanced Patterns for Production Systems
Hybrid search combining BM25 lexical matching with semantic embeddings improves recall by 15-25%. Real-time data integration and structured RA enable advanced use cases, such as live dashboards and database querying.
Quality Enhancers:
- Hybrid retrieval: Combine keyword search (BM25) with vector similarity for better coverage
- Cross-encoder reranking: Use BERT-style models for precision improvements
- Query expansion: Automatically rephrase questions to improve retrieval
- Metadata filtering: Combine semantic search with structured filters
Emerging Patterns:
- Structured RAG: Query SQL databases and knowledge graphs alongside text
- Real-time integration: Stream live data updates via webhooks
- Multi-modal RAG: Process documents with images, charts, and tables
- On-device deployment: Privacy-first mobile implementations
Case study: An e-commerce platform combined product catalogs (structured data) with support documentation (unstructured) using GraphRAG. Customer service quality scores improved 23% because agents could access both inventory details and troubleshooting steps in a single query.
Frequently Asked Questions
Do Long-Context LLMs Make RAG Unnecessary?
Long-context models complement rather than replace RAG. Even with million-token contexts, RAG provides fresher data, explicit citations, and cost efficiency for large knowledge bases.
Context windows facilitate complex reasoning over provided documents, but RAG excels at identifying relevant information from vast and changing datasets.
What Chunk Size Should I Start With?
Begin with 500-800 tokens and 10-20% overlap. Adjust based on your content type. Technical documentation benefits from larger chunks, while FAQ content works better with smaller sections.
Which Vector Database for Small Teams?
pgvector offers the best cost-to-performance ratio for teams already using PostgreSQL. Pinecone offers managed convenience, while Weaviate strikes a balance between open-source flexibility and enterprise features.
How Do I Prevent Prompt Injection in RAG?
Sanitize user inputs, use structured prompts with explicit delimiters, and implement output filtering to ensure data integrity. Never directly concatenate user input with system prompts.
When Should I Fine-Tune Instead of RAG?
Fine-tune for consistent style, tone, or format requirements. Use RAG for knowledge that changes frequently or requires source attribution.
Ready to build more innovative AI apps? RAG transforms unreliable LLMs into trustworthy knowledge systems. Start with basic similarity search, measure quality religiously, and scale incrementally.
The key insight I’ve learned from dozens of implementations: perfect is the enemy of good. Get your RAG pipeline working with simple components first, then optimize based on honest user feedback.
Your users will appreciate AI that genuinely understands its content.