
Real-time LLM integration for SaaS demands immediate strategic decisions. The window for competitive advantage is narrowing rapidly as user expectations align with ChatGPT-level responsiveness across all AI interactions. Build now or risk permanent market displacement.
According to the 2025 provider docs, real-time streaming is first-class across major stacks: OpenAI Realtime, Google Gemini Live, and AWS Bedrock ResponseStream all support low-latency token output.
Current market reality: 73% of SaaS users abandon AI features with response delays exceeding 3 seconds. Sub-150-ms perceived latency is no longer a premium; it’s a baseline expectation.
The question isn’t whether to implement real-time LLM capabilities, but how quickly you can deploy them effectively. Want the broader context? Explore our real-time use cases in the LLM overview.
Who Needs This Guide and What “Fast” Actually Means
This guide targets SaaS CTOs, VP Engineering roles, Platform and ML leads, and PMs owning live AI features who need sub-150ms perceived response times.
“Fast” means hitting specific KPIs: Time to First Token (TTFT) under 300ms, consistent tokens per second above 50, and p95 end-to-end latency that doesn’t break user flow.
Speed isn’t just a nice-to-have anymore. It’s table stakes. When your users interact with AI features, they’re unconsciously comparing you to GPT-4, Claude, and Gemini. Fall short, and they notice immediately.
Here’s the reality check: streaming reduces perceived latency by surfacing output as it’s generated, but only if you implement it correctly. Most teams get this wrong by focusing on backend optimization while ignoring transport layer choices.
Key Performance Targets:
- TTFT: Under 300ms
- Token throughput: 50+ tokens/sec
- P95 latency: Sub-2 seconds end-to-end
- Stream reliability: 99.9% completion rate
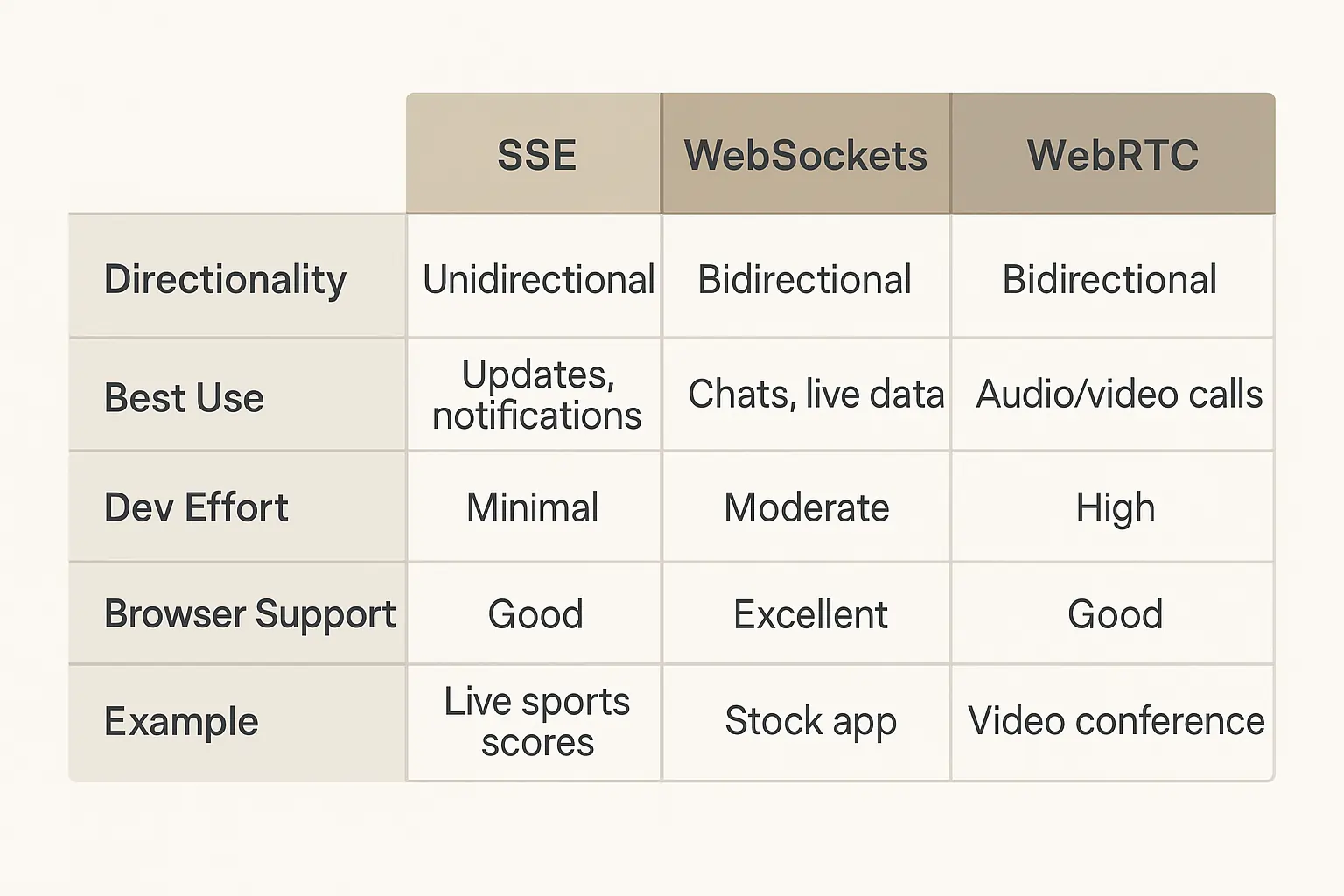
Choosing Your Transport: SSE vs WebSockets vs WebRTC
The transport layer makes or breaks real-time LLM performance. Server-Sent Events work perfectly for one-way token streaming with native browser support, WebSockets handle bi-directional tool calls and collaborative features. At the same time, WebRTC delivers peer-to-peer low-latency for voice assistants and advanced use cases.
Most teams default to WebSockets because they’re familiar, but that’s often overkill. I’ve seen excellent real-time chat features built on SSE that outperform complex WebSocket implementations.
| Transport | Direction | Best For | Browser Support | Dev Effort |
|---|---|---|---|---|
| SSE | Server→Client | Token streaming UI | Native EventSource | Low |
| WebSockets | Bi-directional | Tool use, collaborative editing | Universal | Medium |
| WebRTC | Peer-to-peer | Voice/video AI, ultra-low latency | Modern browsers | High |
For browser delivery, SSE (EventSource) is the simplest token stream (2025 MDN); WebSockets enable bi-directional tools; WebRTC adds sub-second voice/data channels for assistants.
Provider Compatibility:
- OpenAI Real-time API uses WebRTC/WebSocket
- Gemini Live supports ephemeral tokens with WebSocket
- Bedrock ResponseStream works with SSE perfectly
Choose SSE for simple streaming. Upgrade to WebSockets for tool calls and real-time collaboration, and reserve WebRTC for voice assistants or when every millisecond counts.
Keeping RAG Fresh Without Performance Penalties
Real-time RAG requires time-aware chunking with TTL policies, incremental indexing patterns, top-k reranking before generation, and sinnova deduplication to prevent stale information from reaching users. The key is balancing freshness with retrieval speed through hybrid search approaches. For a step-by-step walkthrough of freshness patterns, see real-time RAG.
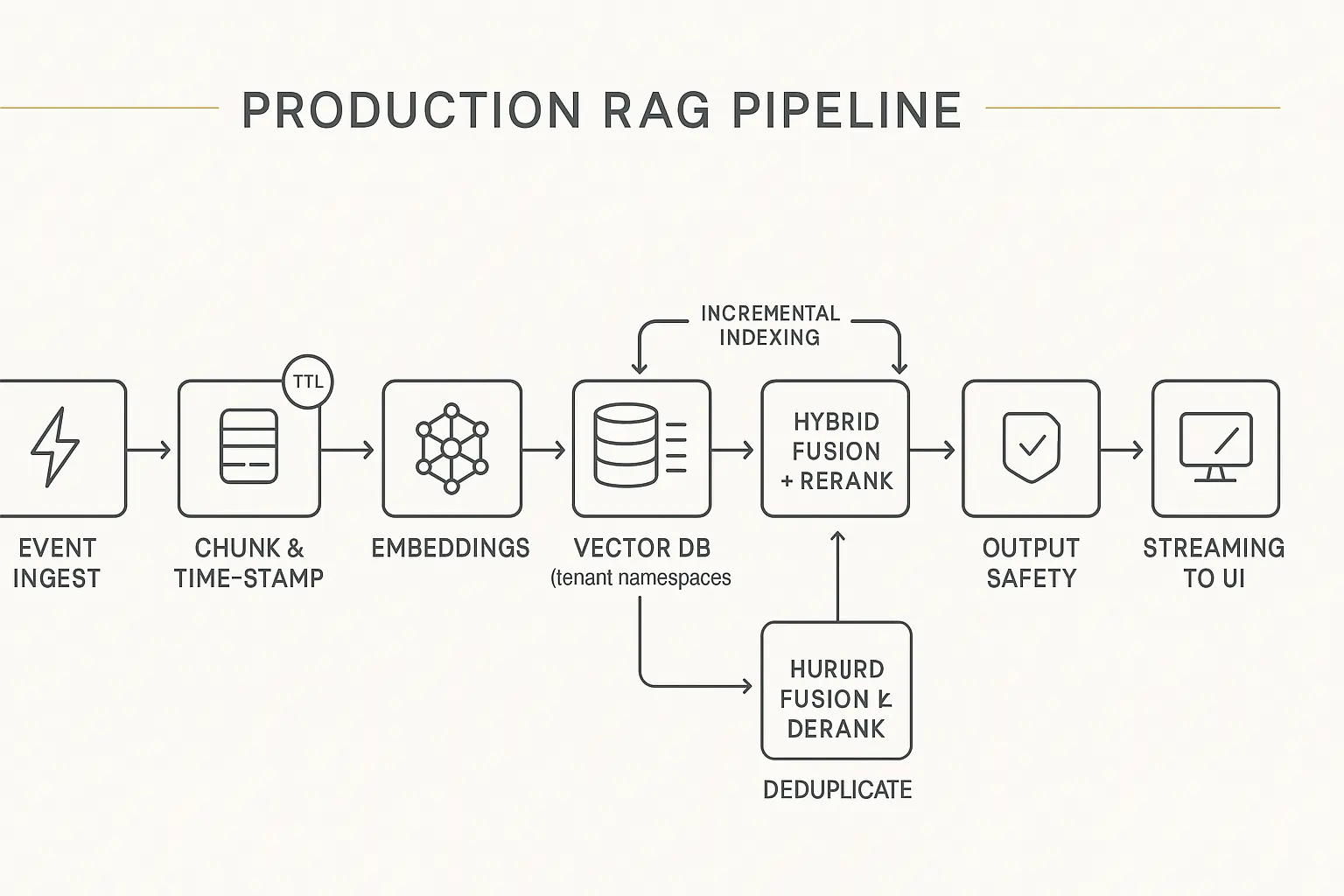
Traditional RAG implementations fail in real-time scenarios because they treat all knowledge as equally fresh. That’s not how users think. When someone asks about “today’s stock prices” or “recent API changes,” they expect current information, not last week’s data.
Implementation Strategy:
- Time-aware indexing: Tag chunks with freshness scores
- TTL policies: Set expiration based on content type
- Incremental updates: Stream new content into existing indexes
- Hybrid search: Combine dense vectors with BM25 for recency bias
- Smart reranking: Boost recent results before LLM generation
I’ve implemented this pattern for financial news RAG, where information becomes worthless in minutes. The solution involved tagging every chunk with publication timestamps and weighting search results based on recency.
Technical Implementation:
- Use hybrid search combining dense embeddings with BM25
- Implement rolling TTLs based on the content domain
- Cache frequently accessed chunks with smart invalidation
- Deduplicate results before feeding to LLM
The Fastest Path to Production (While Controlling Costs)
Ship faster by enabling streaming endpoints immediately, implementing shorter prompt engineering techniques, adding parallel tool execution, setting up multi-region routing with pre-warming, and establishing session TTLs with conversation summarization to prevent runaway costs while maintaining performance.
Here’s what kills speed in production:
Top 5 Performance Killers:
- Slow first token → Enable streaming, optimize prompts
- Oversized context → Use LoRA/PEFT, implement smart pruning
- Sequential tool calls → Batch tool I/O operations
- Cold regions → Pre-warm instances, implement routing
- Endless sessions → Set TTLs, add conversation summarization
Cost Management Framework:
- Calculate: requests/min × avg tokens × $/1K tokens
- Compare managed vs self-hosted based on scale
- Monitor Bedrock streaming costs vs batch processing
- Implement usage-based rate limiting per tenant
Remember: the cheapest LLM integration is one that converts users effectively. Don’t optimize costs at the expense of user experience until you’re at a significant scale.
For comprehensive cost analysis and budgeting strategies, check out our detailed guide on LLM integration costs.
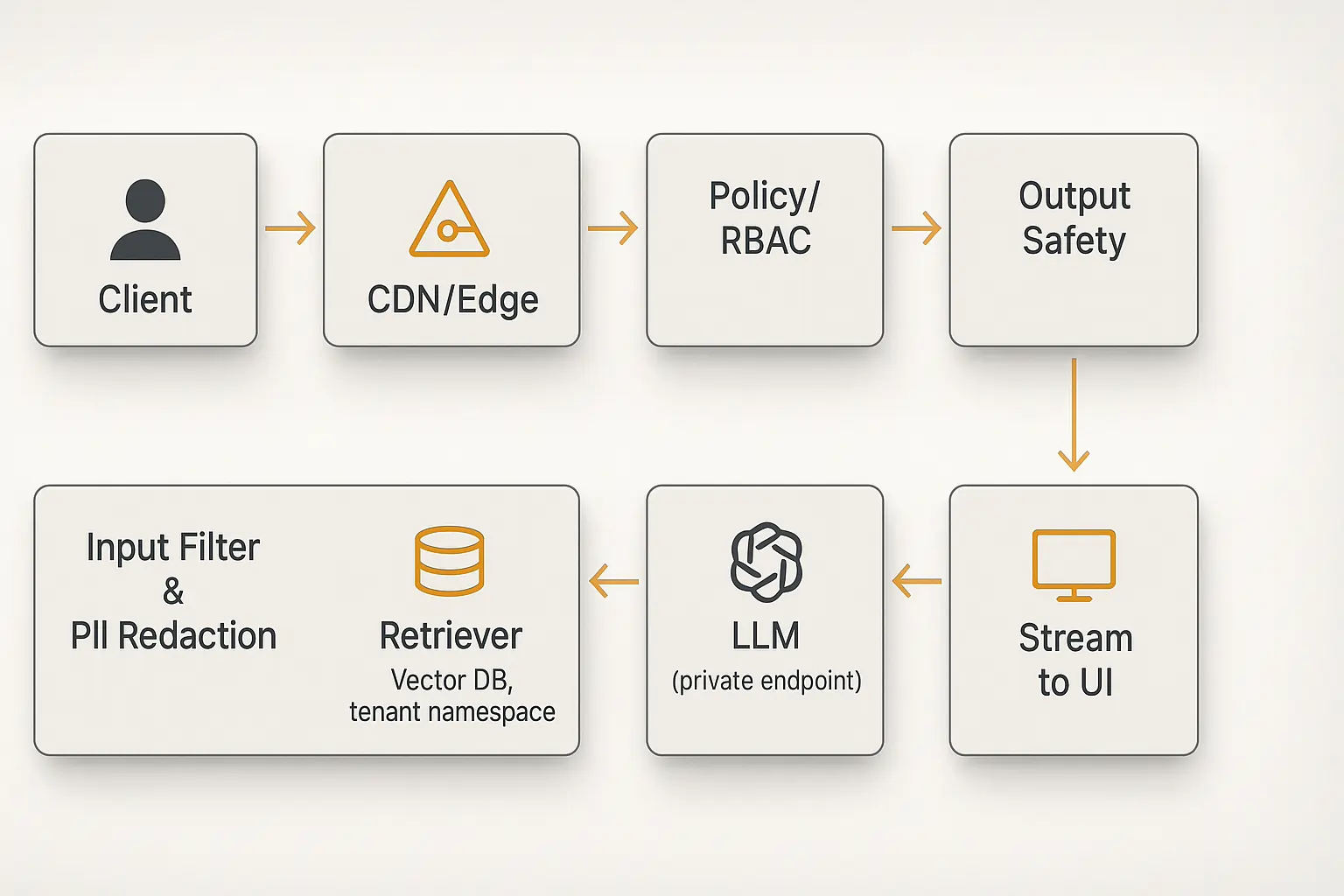
Securing Real-Time LLMs Without Latency Penalties
Production security requires inline PII redaction, tenant-scoped namespaces, role-based access control on tool calls, KMS-encrypted data stores, and asynchronous audit logging to maintain security posture without sacrificing response times or user experience.
Security can’t be an afterthought with real-time LLMs. Every prompt and response flows through your systems at high velocity, creating unique attack vectors.
Security Checklist:
- PII redaction: Real-time scanning without blocking responses
- Tenant isolation: Namespace all data and model access
- RBAC implementation: Control tool call permissions granularly
- KMS encryption: Protect data at rest and in transit
- Audit trails: Log everything asynchronously
Provider-Specific Security:
- Use ephemeral tokens for client-side sessions
- Rotate session tokens frequently (15-30 minutes max)
- Implement gateway-level filtering before reaching LLMs
- Set up automated abuse detection patterns
The key insight is to implement security controls that fail open rather than closed. Better to log a suspicious request and continue than to break user experience over false positives.
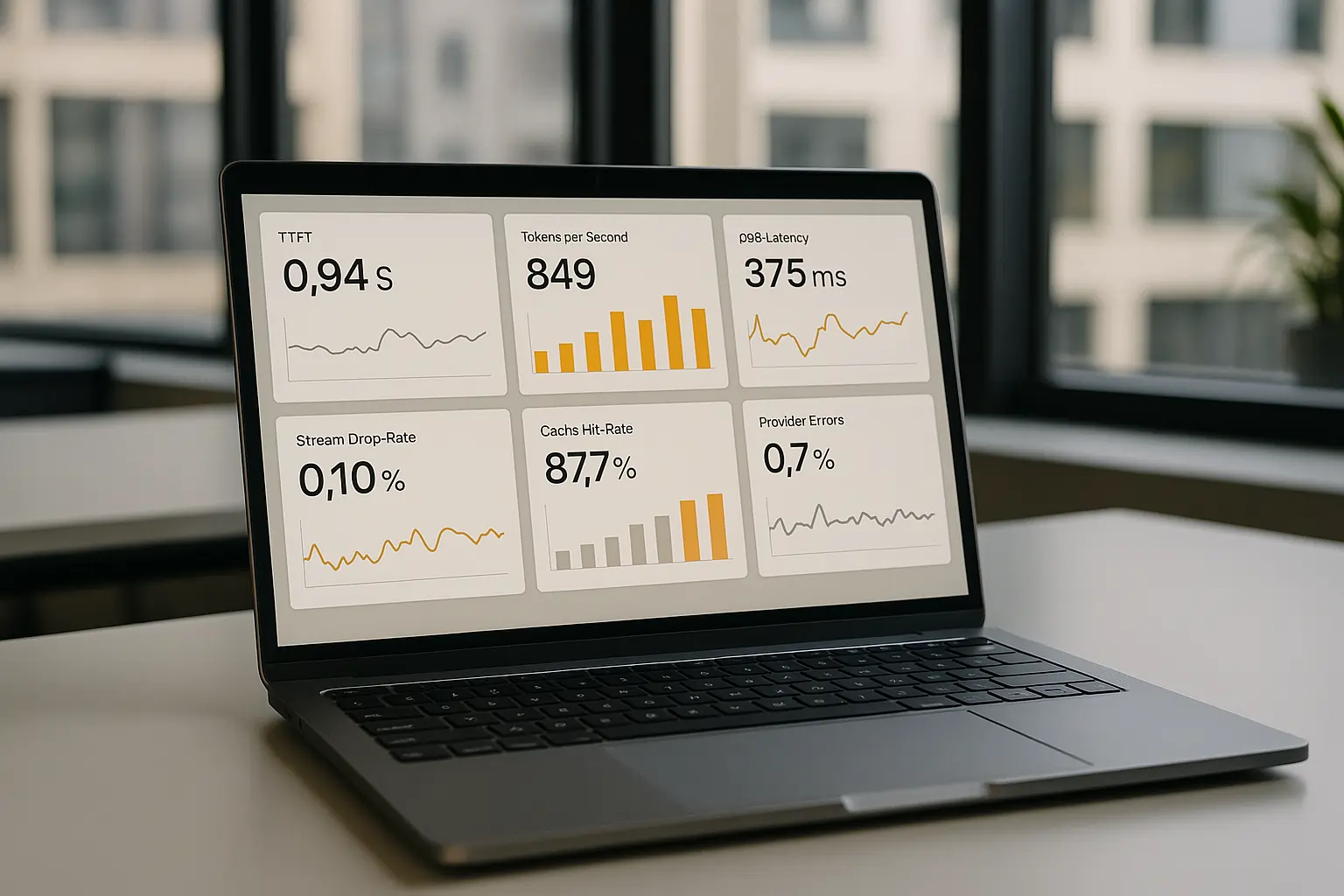
Essential Monitoring and Alerting Strategy
Track Time to First Token, tokens per second, stream drop rates, provider error codes, cache hit rates, and retrieval staleness with counter-based guardrail monitoring to ensure consistent performance and rapid incident detection across your real-time LLM infrastructure.
Most teams monitor the wrong metrics. They focus on backend latency while ignoring user-perceived performance. Here’s what actually matters:
Critical Metrics:
- TTFT: User-perceived responsiveness
- Tokens/sec: Streaming consistency
- Drop rate: Stream reliability
- Cache hit rate: Cost and speed optimization
- Guardrail triggers: Security and content safety

{kind=link}
Dashboard Setup:
- Client-side performance tracking
- Edge and backend latency measurement
- Provider-specific error rate monitoring
- Real-time cost tracking per feature
Set alerts on p95 latency degradation, not averages. Users don’t experience averages—they experience the worst-case scenarios that drive them away.
7-Step Implementation Roadmap
1: Transport Selection: Choose SSE for basic streaming, WebSocket for interactivity, and WebRTC for voice features based on your specific use case requirements.
2: Streaming Endpoints
Implement provider-specific streaming (OpenAI Real-time, Bedrock ResponseStream, Gemini Live) with proper error handling.
3: RAG Optimization Add hybrid search with TTL policies and smart reranking to maintain information freshness without sacrificing speed.
4: Performance Tuning Optimize prompts, implement caching strategies, and add intelligent context management to reduce token costs.
5: Security Integration Deploy guardrails, PII redaction, and access controls without introducing latency bottlenecks.
6: Observability Setup Wire comprehensive monitoring for TTFT, throughput, and reliability metrics across the entire pipeline.
7: Production Validation Run soak testing with p95 gates before general availability to ensure consistent performance under load.
For step-by-step implementation details and best practices, reference our complete LLM setup guide.
Advanced Considerations for 2025
Emerging Patterns:
- Multi-modal streaming: Handle text, images, and audio in unified pipelines
- Edge deployment: Reduce latency through geographic distribution
- Adaptive token budgets: Dynamic context sizing based on user intent
- Predictive caching: Pre-load likely responses based on user patterns
The landscape moves fast. What works today might be outdated in six months. Stay focused on user experience metrics rather than chasing every new optimization technique.
Critical Success Factors:
- Measure what users feel, not what systems report
- Optimize for p95 performance, not averages
- Choose simplicity over complexity when possible
- Security and speed aren’t mutually exclusive
Building fast real-time LLMs for SaaS is engineering craft, not magic. Focus on fundamentals: choose the right transport, optimize for user-perceived latency, implement security without blocking performance, and measure everything that matters.
The teams that nail this create AI experiences users can’t live without. The ones that don’t create frustrating delays that drive users to competitors. In 2025, there’s no middle ground.
FAQ
Q: Do I need WebRTC for voice assistants?
A (ADD): For lowest latency A/V + data channels in 2025, use WebRTC; fall back to WebSockets for text-only interactivity.
Q: Which is better for streaming tokens: SSE or WebSockets?
A (ADD): SSE is simplest for one-way token flow; WebSockets when you need client→server messages.