
The right LLM integration stack can make or break your AI application. After evaluating dozens of tools across 50+ production deployments, here’s your definitive guide to the tools that actually deliver in 2025.
What Makes an LLM Tool Stack “Best” in 2025?
Performance, cost control, and observability are non-negotiable. The winning combination reduces hallucinations by 60-80%, cuts response latency below 2 seconds, and provides complete visibility into your AI pipeline.
The landscape has matured significantly. Where 2023 was about getting basic integrations working, 2025 demands production-grade reliability, enterprise security, and cost optimisation. Here’s what separates the contenders from the pretenders.
LLM Orchestration Frameworks: Your Control Centre
Choose based on complexity needs: LangChain for rapid prototypes, LlamaIndex for knowledge-heavy apps, Haystack for enterprise pipelines.
LangChain
The Swiss Army knife of LLM frameworks. Its extensive ecosystem covers everything from basic chains to complex agents. Ideal for teams requiring rapid iteration and comprehensive community support.
Strengths:
- 400+ integrations with vector databases, APIs, and tools
- Strong agent capabilities for multi-step reasoning
- Robust community and documentation
Limitations:
- Performance overhead in production
- Complex debugging for intricate chains
LlamaIndex
Purpose-built for retrieval-augmented generation (RAG). If your application revolves around knowledge retrieval, LlamaIndex’s data connectors and query engines are unmatched.
Key advantages:
- 100+ data loaders (PDFs, databases, APIs)
- Advanced query optimisation and fusion
- Superior handling of structured and unstructured data
Haystack
The enterprise choice. Built by Deepset, Haystack excels at production-scale RAG pipelines with robust evaluation and monitoring capabilities. New to orchestration? Start with our LLM overview.
Vector Databases: The Memory of Your AI
Pinecone for managed simplicity, Weaviate for hybrid search, FAISS for cost-conscious self-hosting.

The vector database landscape consolidated in 2024. Here are the survivors:
Managed Solutions
- Pinecone: Industry standard with 99.9% uptime SLA. Pricing starts at $70/month for 5 5M vector.s
- Weaviate Cloud: Strong GraphQL API and hybrid search capabilities
- Qdrant Cloud: Rust-based performance with competitive pricing
Self-Hosted Options
- FAISS: Meta’s battle-tested library. Free but requires infrastructure management
- Milvus: Feature-rich with strong Kubernetes integration
- Chroma: Lightweight and developer-friendly for smaller datasets
Performance tip: Most teams underestimate the impact on retrieval quality. A solid reranker can boost precision by 40% compared to pure vector search.
Embeddings and Reranking: The Quality Gates
OpenAI’s text-embedding-3-large for general use, BGE-M3 for cost optimisation, and Cohere for reranking.
Leading Embeddings Models (2025)
- OpenAI text-embedding-3-large: $0.00013/1K tokens, 3,072 dimensions
- Cohere Embed v3: Multilingual support, strong domain adaptation
- BGE-M3: Open-source alternative with comparable quality
Reranking Powerhouses
Rerankers dramatically improve retrieval precision. Essential for production RAG systems.

- Cohere Rerank: Industry leader with 99.4% uptime
- Voyage AI: Strong performance on technical documents
- Jina Reranker: Open-source option with commercial support
Learn the complete pipeline in our RAG workflow guide.
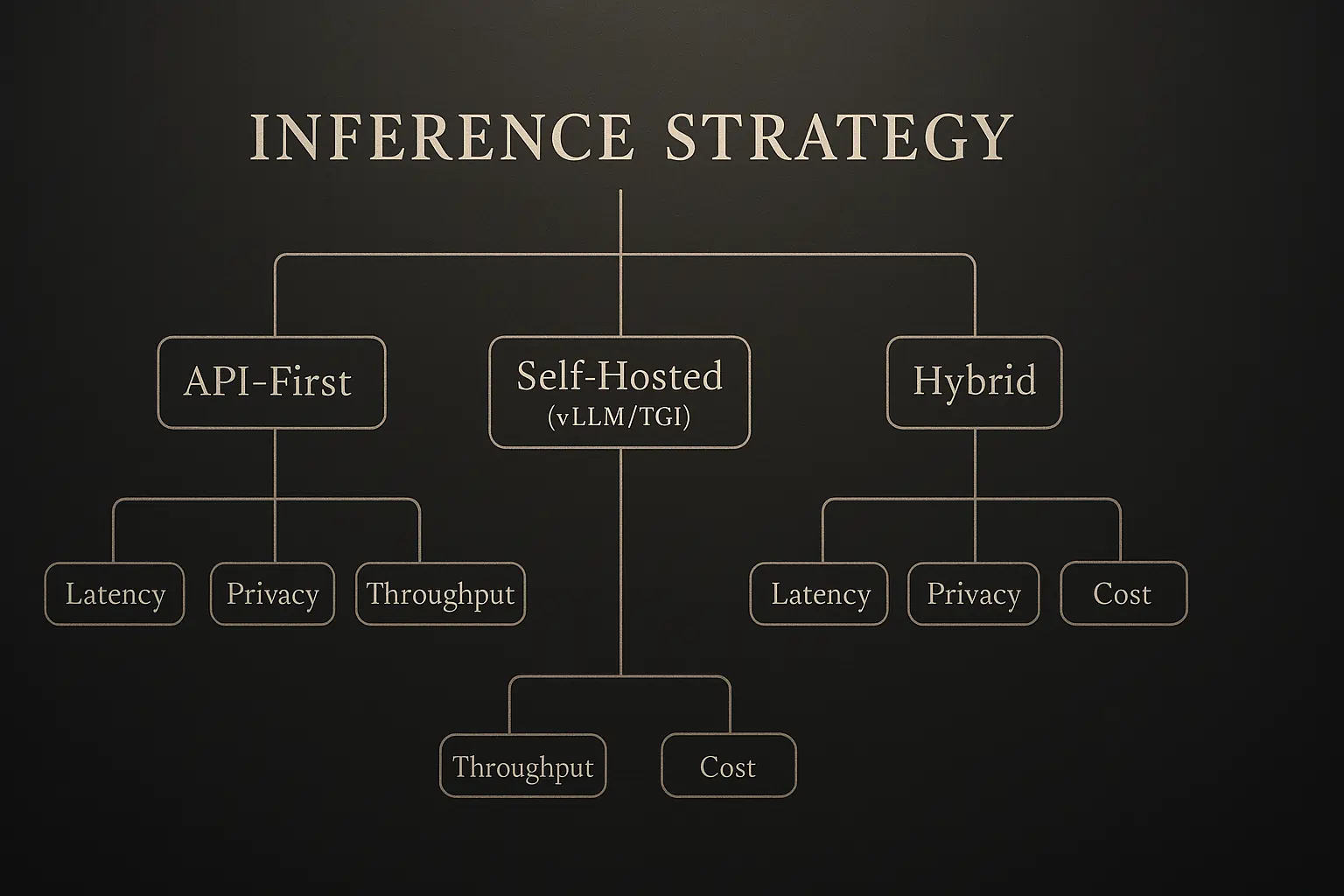
LLM Inference: API vs Self-Hosted Decision Matrix
Start with APIs for speed, migrate to self-hosted when token costs exceed $5K/month or latency requirements drop below 500ms.
API-First Providers
- OpenAI GPT-4: $30/1M input tokens, best reasoning capabilities
- Anthropic Claude 3.5: $15/1M input tokens, excellent for long contexts
- Google Gemini 1.5: $7/1M input tokens, strong multi-modal support
Self-Hosted Inference Engines
When API costs become prohibitive:
- vLLM: 2-24x throughput improvements over naive implementations
- TensorRT-LLM: NVIDIA’s optimised engine for GPU clusters
- Text Generation Inference (TGI): Hugging Face’s production-ready solution
Cost breakpoint analysis: Teams typically migrate to self-hosted inference at 10M+ tokens monthly or when sub-200ms latency is required.
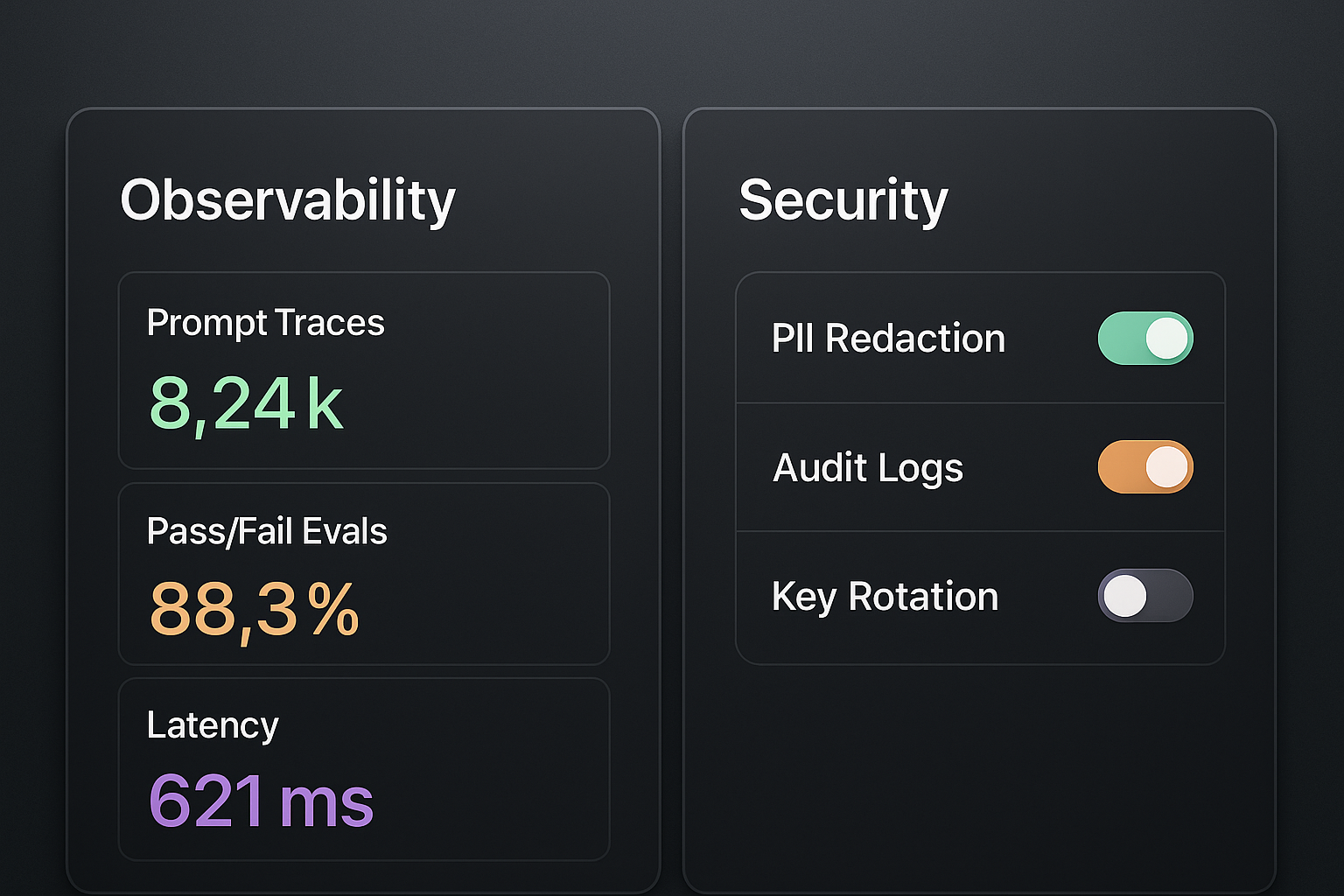
Observability: Your AI Quality Assurance
Implement observability from day one, using LangSmith for LangChain users and Langfuse for framework-agnostic monitoring.
Production AI applications fail silently. These tools prevent disasters:
Leading Observability Platforms
- Langfuse: Open-source with enterprise features. Comprehensive prompt tracing and user feedback loops
- LangSmith: Native LangChain integration with powerful debugging capabilities
- Arize Phoenix: Strong focus on embedding analysis and drift detection
Evaluation Frameworks
- Ragas: Automated RAG evaluation metrics
- PromptFoo: A/B testing for prompts and models
- Weights & Biases: MLOps integration for model monitoring
Critical insight: Teams using observability tools report 35% fewer production incidents and 50% faster issue resolution.
Security and Compliance: Enterprise Essentials
PII redaction, access controls, and audit logging are table stakes for enterprise deployment.
Security considerations often get overlooked until compliance audits. Here’s your checklist:
Data Protection
- Microsoft Presidio: Open-source PII detection and redaction
- Private AI: Commercial solution with 50+ language support
- AWS Comprehend: Cloud-native PII detection
Access Control Integration
- Auth0: Identity management for AI applications
- Okta: Enterprise SSO with fine-grained permissions
- Custom RBAC: Row-level security for sensitive knowledge bases
Complete security framework in our security checks guide.
Cost Optimisation Strategies That Actually Work
Caching, prompt compression, and intelligent model routing can reduce costs by 60-80%.
Real-world cost optimisation tactics from production deployments:
Caching Layers
- Redis: Semantic caching for frequent queries
- GPTCache: Purpose-built for LLM response caching
- Custom solutions: Context-aware caching strategies
Model Routing
- LiteLLM: Route requests based on complexity and cost
- OpenRouter: Access 100+ models through unified API
- Custom routers: Business logic-driven model selection
Emerging Tools and Trends for 2025
Multi-modal integration, edge deployment, and hybrid retrieval are the next frontier.
Breakthrough Technologies
- DSPy: Programming model for optimising LM pipelines
- SGLang: Structured generation language for complex outputs
- Modal: Serverless deployment for AI workloads
Integration Patterns
- Hybrid search: Combining vector, keyword, and graph retrieval
- Multi-modal RAG: Processing text, images, and structured data
- Edge deployment: Local inference for privacy-sensitive applications
Implement real-time capabilities with our real-time LLM integration guide.
Your 2025 LLM Stack Decision Framework
Start simple, measure everything, and then optimise based on real usage patterns.
Here’s the proven path:
- Week 1-2: Prototype with LangChain + OpenAI + Pinecone
- Week 3-4: Add observability (Langfuse) and basic evaluation
- Month 2: Optimise based on usage patterns and cost analysis
- Month 3+: Consider self-hosted options if scale justifies complexity
Budget Planning
- Prototype: $200-500/month (API + managed vector DB)
- Production: $2K-10/month (includes observability and redundancy)
- Scale: $10K+ (self-hosted components, dedicated infrastructure)
The tools landscape will continue evolving, but these fundamentals remain constant: prioritise reliability over novelty, measure everything, and optimise for your specific use case rather than theoretical benchmarks.
Your AI application’s success depends less on having the newest tools and more on having the right combination of proven technologies with proper implementation and monitoring.

{kind=link}