
start with genetics and coding fundamentals, then use public datasets, tools like AlphaMissense or UGENE, and structured validation methods to build real projects. This guide explains what AI bioinformatics is, why it matters, the skills you need, the best tools, validation steps, ethical guardrails, and future trends giving you a smarter learning roadmap for 2025.
TL;DR
-
What it is: AI-driven bioinformatics applies machine learning to gene editing and genomic data.
-
Why it matters: Faster, more accurate predictions, lower costs, scalable discoveries.
-
How to start: Learn biology + Python, use public datasets, practice with tools like UGENE and GenoCAD.
-
Validation: Always cross-validate and use explainable AI methods.
-
Future: DNA large language models, quantum genomics, and generative biology are emerging fast.
What is AI-driven bioinformatics in genetic engineering?
AI-driven bioinformatics in genetic engineering means using algorithms and models to design, predict, and analyze gene edits at scale.
It merges wet-lab science with computation, transforming trial-and-error into data-driven workflows.
Example: DeepMind’s AlphaMissense classifies 71M missense mutations into pathogenic or benign, streamlining variant interpretation (DeepMind, 2023).
Mini Glossary
- CRISPR-Cas9: the “molecular scissors” for gene editing
- DNA-LLM: large language models trained on nucleotide sequences
- Variant effect prediction: scoring the impact of mutations
- XAI: explainable AI to interpret model results
Why integrate AI into genetic engineering?
AI integration accelerates discovery, reduces experimental costs, and improves precision in predicting genetic outcomes.
With AI, researchers detect subtle DNA patterns, optimize CRISPR targets, and automate pipelines.
Pros / Cons
| Pros | Cons |
|---|---|
| Faster variant scoring | Overfitting risks |
| Genome-wide scale | Opaque black-box models |
| Lower lab costs | Dataset bias issues |
| Predict off-targets | Regulatory uncertainty |

GPU pipelines like NVIDIA Parabricks speed up whole genome workflows by 135× vs CPU-only methods (NVIDIA, 2023).
Large Action Models explain how agentic AI systems scale similar workloads.
What AI/ML models power genetic predictions today?
Leading models include large language models, generative AI, and hybrid ML pipelines that combine domain features with deep learning.
They interpret long sequences, model structural context, and propose novel designs.
Comparison Table
| Model | Use Case | Strength | Weakness |
|---|---|---|---|
| DNA-LLM | variant/regulatory prediction | handles long dependencies | compute heavy |
| Generative AI | novel DNA/protein design | creative sequences | validity concerns |
| Hybrid ML | variant effect scoring | interpretable, modular | limited feature space |
| Agentic pipelines | orchestrate workflows | automation, multi-tool | complex to debug |
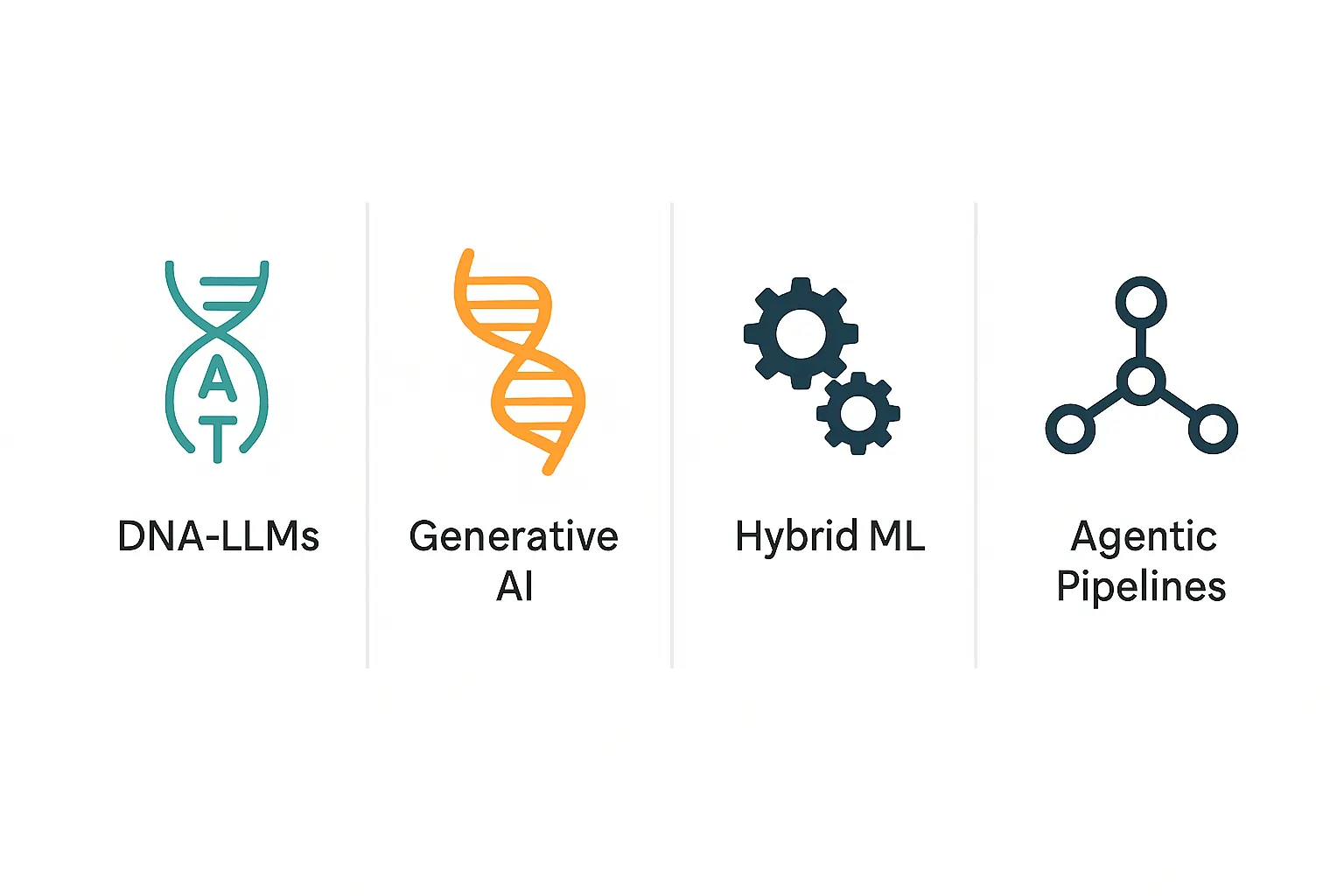
Example: DNA-LLMs treat nucleotides like text tokens, enabling predictions across massive genomes (Wikipedia, 2024).
Understanding Artificial Intelligence provides background on how these models evolve.
How do I build a learning path for AI + genetic engineering?
Start with biology basics, add programming + statistics, then progress into bioinformatics tools, ML modeling, and validation projects.
This staged approach avoids overwhelm while building real-world capability.
5 Steps Roadmap
- Learn genetics + molecular biology
- Pick up Python, R, and statistics
- Explore alignment and annotation tools
- Build small models on public genomic datasets
- Validate results with benchmarks and explainability
Example: NCBI offers open variant sets you can use to train a classifier for pathogenic vs benign mutations.
see Mastering AI for Greater Search Visibility to understand how AI optimization strategies apply across domains, including bioinformatics.
Prerequisites Table
| Skill Area | Why It Matters |
|---|---|
| Genetics | foundation for gene editing |
| Programming (Python) | model building & automation |
| Statistics | ensures valid inferences |
| Bioinformatics | connects sequence data & ML |
Which tools, platforms & agents should I learn?
Core tools include UGENE for alignment, AlphaMissense for variant effect prediction, GenoCAD/Gene Designer for construct design, and AutoBA for automated pipelines.
Together, they form the ecosystem of genetic AI workflows.
Tool Comparison
| Tool | Purpose | Strengths | Limitations |
|---|---|---|---|
| UGENE | GUI bioinformatics | alignment, annotation | less scalable |
| AlphaMissense | mutation prediction | proteome-wide classification | compute heavy |
| Gene Designer | DNA constructs | codon optimization | legacy interface |
| AutoBA | pipeline automation | agent orchestration | new, evolving |
Fact: UGENE integrates GUI + CLI workflows, making it beginner-friendly while supporting power users (UGENE WIKI, 2023).
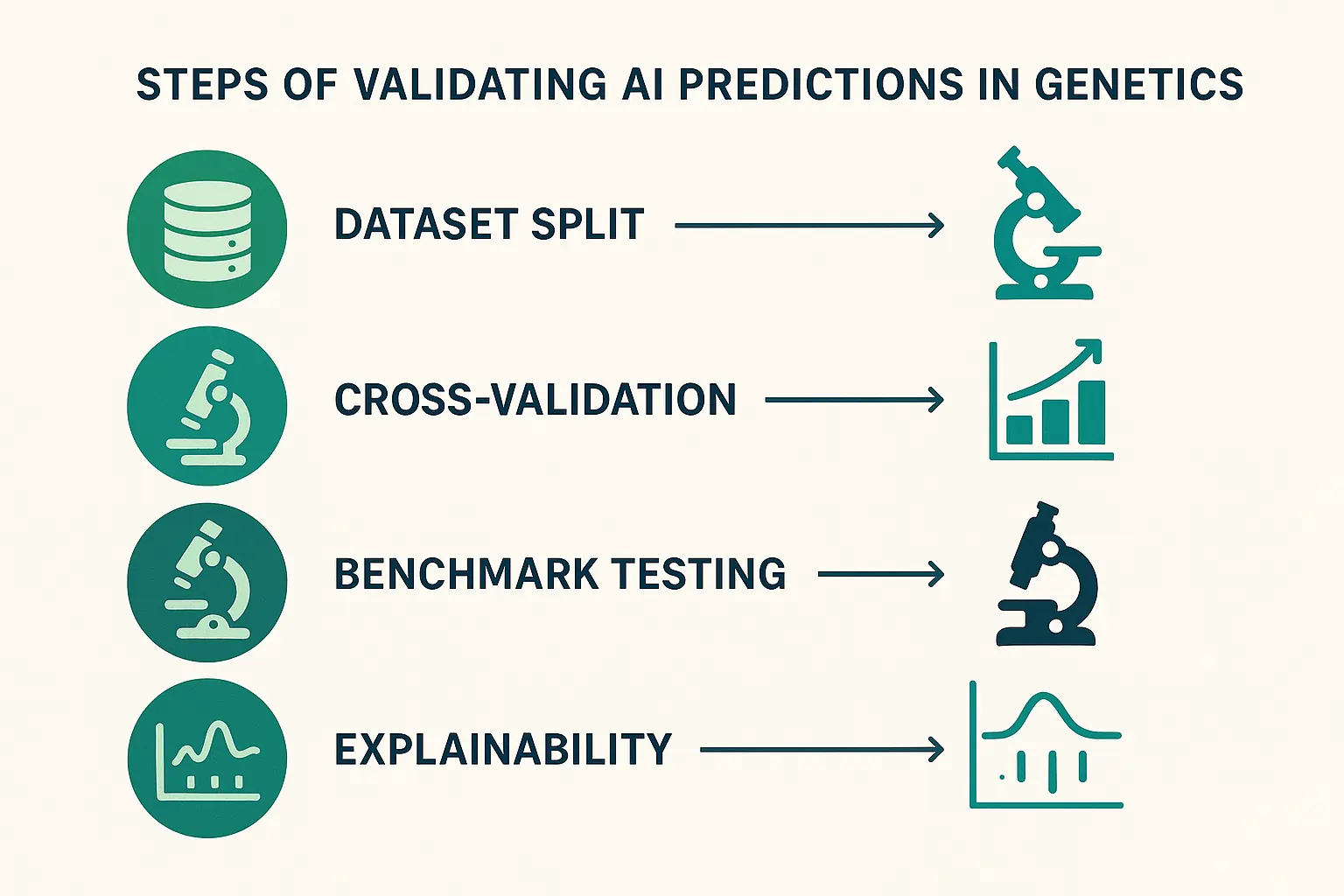
How do I validate AI predictions in genetic engineering pipelines?
Validation involves testing models on benchmark datasets, cross-checking results with biological assays, and utilizing explainability to ensure reliability.
Without validation, predictions risk being misleading or unsafe in both clinical and laboratory use.
Checklist: Key Validation Steps
- Train/test split to prevent data leakage
- Cross-validation for robustness
- Benchmark against known datasets (ClinVar, gnomAD)
- Biological replication or wet-lab verification
- Apply explainability (e.g., SHAP, LIME)
Example: NVIDIA reported that GPU-accelerated workflows reduce human error in variant calling by increasing reproducibility (NVIDIA, 2023).
Related read: How AI Detection Works detection methods parallel explainability in genomics, ensuring predictions can be trusted.
What pitfalls should I avoid when applying AI in genetics?
Overfitting, biased datasets, and lack of interpretability are the most common pitfalls.
AI isn’t magic unchecked models can generate false confidence and mislead experiments.
Pros / Cons Style
| Pitfall | Why It Matters |
|---|---|
| Overfitting | great on training, fails in reality |
| Data leakage | inflated performance metrics |
| Bias in datasets | unfair or skewed predictions |
| Black-box models | low trust, more complex regulation |
How do I apply explainable AI (XAI) in genomics?
Utilize XAI methods, such as SHAP, attention maps, and feature attribution, to make predictions more interpretable.
This helps regulators, peers, and researchers trust results.
Mini-Table: XAI Methods
| Method | Application | Limitation |
|---|---|---|
| SHAP values | feature importance | computationally heavy |
| Attention maps | highlight sequence motifs | not always biological |
| LIME | local interpretability | unstable across runs |
Stat: A 2023 review on explainable AI in genomics emphasized that interpretability improves reproducibility and adoption (ARXIV, 2023).
What ethical and regulatory considerations must I take into account?
You must safeguard privacy, address bias, prevent dual-use risks, and comply with U.S. agencies such as the NIH and FDA.
AI makes gene editing faster but also riskier if abused.
Top 5 Risk Domains
- Data privacy & consent
- Algorithmic bias
- Off-target gene edits
- Dual-use misuse (biosecurity)
- Regulatory oversight gaps
Example: The FDA requires clear documentation for AI-assisted medical workflows; the NIH enforces biosafety guidelines.
What are the future trends in AI + genetic engineering?
DNA large language models, agentic systems, quantum AI, and generative biology are reshaping the field in 2025 and beyond.
They extend beyond incremental gains pointing toward new research paradigms.
Trends List (2025–2026)
- DNA-LLMs modeling whole genomes
- Generative biology designing synthetic proteins
- Agentic pipelines automating wet-lab + dry-lab tasks
- Quantum genomics is speeding up alignment/optimization
- Multimodal AI linking omics layers (DNA + RNA + proteomics)

Example: DNA-LLMs now treat nucleotides as language tokens, enabling contextual predictions across gigabase genomes (Wikipedia, 2024).
Related read: SuperAI 2024 showcases cutting-edge developments, many of which overlap with DNA-LLMs, generative biology, and quantum AI.
How can I build a sample project portfolio?
Start small design a CRISPR off-target predictor using public datasets, then expand into multi-omics pipelines.
Document results clearly to showcase skills to labs, employers, or grad programs.
5-Step Mini Project Blueprint
- Choose a public CRISPR dataset
- Engineer features (guide sequence, mismatch count)
- Train a classifier (logistic regression, LLM)
- Validate using cross-validation + benchmarks
- Document with visuals + explainability output
Example Project: Predict CRISPR off-target scores using NCBI data + SHAP interpretation.
Pro Tip: Publish results on GitHub or a personal blog to boost credibility.
FAQ: People Also Ask
- How do I start learning AI in genetic engineering?
Begin with biology + coding, then build small predictive projects with public datasets. - What are the best AI tools for genetic engineering?
AlphaMissense, UGENE, AutoBA, and DNA-LLMs lead in 2025. - How to validate AI predictions in CRISPR editing?
Use benchmarks, cross-validation, and explainability before trusting predictions. - Which U.S. programs cover AI + bioinformatics for genetics?
Universities like Stanford and MIT, as well as online providers, now offer hybrid certificates. - What are the ethical risks of AI in genetic engineering?
Bias, privacy loss, off-target edits, dual-use misuse, and lack of explainability. - Does AI replace traditional bioinformatics entirely?
No, AI augments existing methods but doesn’t eliminate classic pipelines.
Conclusion
By combining genetic engineering and AI bioinformatics, you gain a competitive edge in biotech and research.
Stay grounded: validate predictions, respect ethics, and continuously upskill. The U.S. is at the forefront leverage its courses, labs, and resources to stay ahead.

{kind=link}