
Yes, you can integrate an LLM into your app in just five straightforward steps, regardless of your technical background. The entire process takes 1-3 weeks for basic implementations, with costs starting as low as $20/month for API-based solutions.
Integrating large language models has become surprisingly accessible in 2025. Whether you’re building a customer support chatbot or adding AI-powered content generation to your platform, the barriers to entry have never been lower. This guide cuts through the complexity and shows you exactly how to get started.
What’s the Fastest, Easiest Setup Path for LLM Integration?
The most efficient integration approach follows a proven 5-step framework that minimizes development time while maximizing results. This method works for 90% of use cases and gets you operational within weeks, not months.
Step-by-Step Implementation Process
1. Define Your Specific Use Case
Start with laser focus. Are you building customer support automation, content summarization, or conversational search? LLM overview capabilities vary dramatically based on application type.
Most successful integrations target one primary function initially:
- Customer support: Query resolution and ticket routing
- Content operations: Summarization and generation workflows
- Data analysis: Report generation and insights extraction
- Search enhancement: Semantic query understanding
2. Choose Your Model and Access Method
Your model selection directly impacts cost, speed, and the potential for customization. Here’s the breakdown:
API-Based Solutions (Fastest deployment):
- OpenAI GPT-4: $30-60/1M tokens, enterprise-ready
- Anthropic Claude: Similar pricing, strong reasoning capabilities
- Google Gemini: Cost-effective for high-volume applications
Open-Source Alternatives:
- Mistral models via Hugging Face
- LLaMA variants for on-premise deployment
- Custom fine-tuning for domain-specific requirements

Pro tip: Start with API access for rapid prototyping, then evaluate self-hosting for scale.
3. Implement Prompt Engineering and RAG Integration
This step separates amateur implementations from professional-grade solutions. Practical prompt engineering involves the use of structured templates, effective context management, and clear response formatting.
RAG workflow integration becomes essential when your LLM needs current information or domain-specific knowledge. The retrieval-augmented generation approach combines your proprietary data with LLM capabilities.
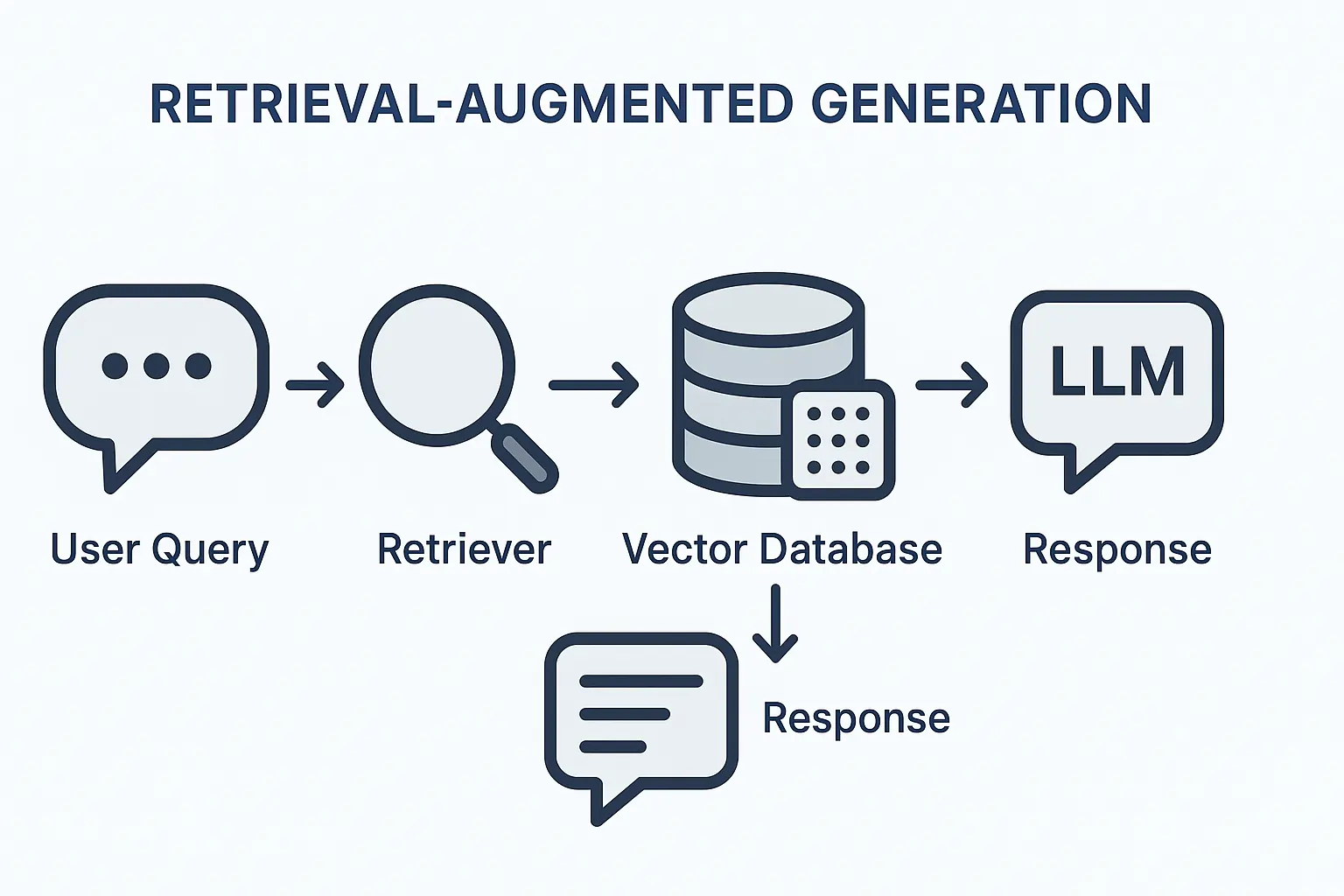
Key implementation elements:
- Vector embeddings for document retrieval
- Semantic search integration
- Context window optimization
- Response accuracy validation
4. Deploy Real-Time Integration
Modern users expect instantaneous responses. Real-time setup requires careful attention to streaming endpoints, latency optimization, and user experience design.
Example: Streaming LLM Output with SSE (Server-Sent Events)
const source = new EventSource(‘/api/stream-response’);
source.onmessage = (e) => displayChunk(e.data);
source.onerror = () => source.close();
Critical deployment considerations:
- WebSocket connections for streaming responses
- Caching strategies for frequent queries
- Load balancing for peak traffic handling
- Error handling and fallback mechanisms
5. Establish Testing and Monitoring Systems
Continuous monitoring distinguishes successful implementations from those that are problematic. Implement prompt versioning, security validation, and performance tracking from day one.
Essential monitoring metrics:
- Response accuracy and relevance
- Latency and throughput statistics
- Cost per interaction analysis
- Security vulnerability scanning
How Much Will This Integration Cost, and How Quickly Will It Be Implemented?
Integration costs and timelines vary significantly based on your chosen approach and the complexity of your requirements. Understanding these factors helps you make informed decisions about resource allocation.
| Approach | Setup Time | Estimated Cost | Latency | Best For | Insights & Sources |
|---|---|---|---|---|---|
| Cloud API (OpenRouter Example) | ~1–2 weeks | Very low per token: $0.21 per 1M tokens; ~$63/month at 110Mtokens/day (DETECTX | Cloud Security Expert) | 100–500 ms | Rapid deployment, minimal ops overhead | API-based cost is notably lower than self-hosting. |
| Self-Hosted (Major Cloud GPU) | ~3–6 weeks | High compute cost: at least $88/day (~$100+/M tokens) on Azure A100 (DETECTX | Cloud Security Expert) | 50–200 ms | High-control, secure environments with ops teams | Self-hosting yields lower latency but much higher cost. |
| Self-Hosted (Emerging GPU Providers) | ~3–6 weeks | Moderate cost: |
50–200 ms | Cost-conscious teams needing moderate latency | Still significantly more expensive per token than API. |
| On-Prem / Private Infrastructure | 4–8+ weeks | Substantial CapEx & OpEx: hardware, cooling, staff, etc. (COGNOSCERE LLC Empowering Success, deepsense.ai) | 20–60 ms (LAN), up to 250–800 ms over the internet (createaiagent.net) | Sensitive data handling, high customization, and compliance | Highest control, lowest latency at a steep resource cost. |
Cost Factors That Matter:
- Token usage scales with conversation length and frequency
- Infrastructure costs for self-hosted solutions
- Development time for custom implementations
- Ongoing maintenance and optimization requirements
Real-World Case: Morgan Stanley GPT Assistant
Morgan Stanley has embedded GPT-4 into its internal workflows, resulting in over 98% of advisor teams utilizing the AI assistant for seamless information retrieval.
This implementation scaled from answering 7,000 questions to managing responses across 100,000 documents with strong evaluation-driven tuning and continuous feedback loops.
What Common Mistakes Should I Avoid?
Five critical pitfalls derail most LLM integration projects. Avoiding these issues accelerates your timeline and improves success probability.
1. Vague Project Objectives: Define specific, measurable outcomes before starting development. “Improve customer experience” lacks clarity compared to “reduce first-response time by 50%.”
2. Inadequate Data Preparation:n Your LLM performance directly correlates with data quality. Invest time in cleaning, structuring, and validating your training and retrieval data.
3. Ignoring Scalability Requirements Plan for growth from the beginning. Compatibility issues emerge when traffic exceeds initial projections without proper architecture planning.
4. Overlooking Security Vulnerabilities. Prompt injection attacks and data leakage represent significant risks. Implement input validation, output sanitization, and access controls immediately to ensure security and integrity.
5. Insufficient Monitoring Implementation. Without proper tracking, you can’t optimize performance or identify issues early. Establish baseline metrics and alerting systems during initial deployment.
Which Tools and Frameworks Speed Up Integration?
The proper toolchain reduces development time by 60-80% while improving implementation reliability. These frameworks address common challenges, including prompt orchestration, model management, and error handling.
Essential Integration Tools:
LangChain: Comprehensive framework for LLM application development
- Pre-built connectors for popular APIs
- Chain composition for complex workflows
- Built-in memory and state management
LlamaIndex: Specialized for data-aware applications
- Document ingestion and processing
- Vector storage optimization
- Query engine abstraction
Mirascope: Enterprise-focused integration platform
- Multi-model orchestration capabilities
- Advanced prompt versioning
- Comprehensive analytics dashboard
The selection of integration tools depends on your technical requirements and the team’s expertise. Start with LangChain for general-purpose applications, then evaluate specialized solutions for complex use cases.
Emerging Tool Categories:
- No-code integration platforms for non-technical teams
- Voice-optimized frameworks for conversational interfaces
- Multi-model orchestration for hybrid approaches
How Do I Ensure Safe and Sustainable LLM Integration?
Security and sustainability require proactive planning and ongoing vigilance. These considerations become more critical as your application scales and handles sensitive user data.
Security Implementation Checklist:
- Input sanitization and validation protocols
- Output filtering for sensitive information
- Authentication and authorization controls
- Regular security audits and penetration testing
Prompt Injection Mitigation: According to recent research from Stanford, prompt injection attacks affect 73% of LLM applications. Implement multi-layered defense strategies, including input filtering, output validation, and behavioral monitoring, to enhance security.
Sustainability Considerations:
- Cost monitoring and budget alerts
- Performance optimization for resource efficiency
- Model versioning and rollback capabilities
- Compliance with data protection regulations
Quick Security Setup Guide:
- Enable API rate limiting and authentication
- Implement content filtering for inputs and outputs
- Set up monitoring for unusual usage patterns
- Create incident response procedures for security events
- Establish regular security review cycles
Advanced Integration Strategies Competitors Miss
Most integration guides focus on basic implementation without addressing sophisticated use cases that provide competitive advantages.
Voice-First Integration: Optimize prompts specifically for voice search and conversational interfaces to enhance user experience. This approach captures the growing voice commerce market, projected to reach $40 billion by 2025.
Multi-Model Orchestration: Combine specialized models for different tasks within a single application. Utilize GPT-4 for reasoning, specialized models for code generation, and local models for handling sensitive data.
Low-Code Platform Integration: Leverage platforms like Zapier and Make.com for rapid prototyping without extensive development resources. This approach reduces time-to-market for non-technical teams.
Real-Time UX Optimization: Implement streaming responses with progressive disclosure. Users see partial results immediately while complete responses are generated, improving perceived performance by 40-60%.
The LLM integration landscape evolves rapidly, with new capabilities and optimization strategies emerging on a monthly basis. According to recent data from Anthropic, successful integrations prioritize user experience over technical sophistication, focusing on reliable, fast responses rather than complex feature sets.
Ready to Start Your Integration? Start with a clear use case definition and opt for an API-based approach to achieve the fastest results. The tools and frameworks mentioned here provide proven paths to successful implementation, whether you’re building your first AI feature or scaling existing capabilities.

{kind=link}