")
LLM integration costs extend far beyond initial licensing fees, encompassing hidden expenses in token usage, infrastructure scaling, engineering time, and long-term maintenance that can inflate budgets by 200-400% beyond initial estimates.
Let me tell you something that’ll make your CFO’s eyes twitch. Last month, a SaaS startup I consulted for budgeted $15,000 for GPT-4 integration.
Six months later? They’re staring at $47,000 in actual costs. The culprit? Hidden expenses nobody talks about in those glossy vendor presentations.
What Are the Hidden Costs of LLM Integration?
Hidden LLM costs emerge from token usage patterns, infrastructure demands, engineering overhead, and maintenance requirements that vendors rarely highlight upfront, creating budget surprises that can derail AI projects.
Think of LLM integration like buying a luxury car. The sticker price is just the beginning. You’ve got insurance, premium fuel, specialized maintenance, and those inevitable upgrades. Large language models follow the same pattern.
Primary Hidden Cost Categories:
- Token consumption patterns that vary wildly based on user behavior
- Infrastructure scaling for compute resources and data storage
- Engineering time for custom implementations and troubleshooting
- Real-time processing overhead that compounds with user volume
- Fine-tuning expenses for model customization and performance optimization
The most brutal surprise? Token costs. While OpenAI advertises GPT-4 at $0.03 per 1,000 tokens for input, real-world applications often generate 3- 5x more tokens than expected due to conversation context, error handling, and retry mechanisms. (Google Cloud AI Pricing)
Why Are LLM Integration Costs Often Overlooked?
Companies underestimate LLM costs because vendors focus on per-token pricing without revealing operational complexities, infrastructure requirements, and the engineering resources needed for production-grade implementations.
Here’s the uncomfortable truth: most cost calculators are fairy tales. They assume perfect efficiency, zero errors, and users who follow predictable patterns.
Reality? Users are chaotic, systems fail, and business impact requires redundancy and monitoring that multiplies baseline costs.(Gartner’s Research on AI)
Common Blind Spots:
- Prompt engineering iterations that consume development cycles
- Knowledge base integration requires specialized data pipelines
- Operational costs for monitoring, logging, and performance optimization
- Compliance overhead for data handling and security requirements
I’ve seen teams spend three months optimizing prompts alone, burning through senior developer time at $150/hour. That’s $72,000 in hidden labor costs before processing a single user query.
What Are the Main Hidden Costs in LLM Integration?
The four major hidden cost categories are engineering setup ($20,000-$80,000), token usage variability (2-5x projections), infrastructure scaling (30-60% of total costs), and ongoing maintenance ($5,000-$15,000 monthly).
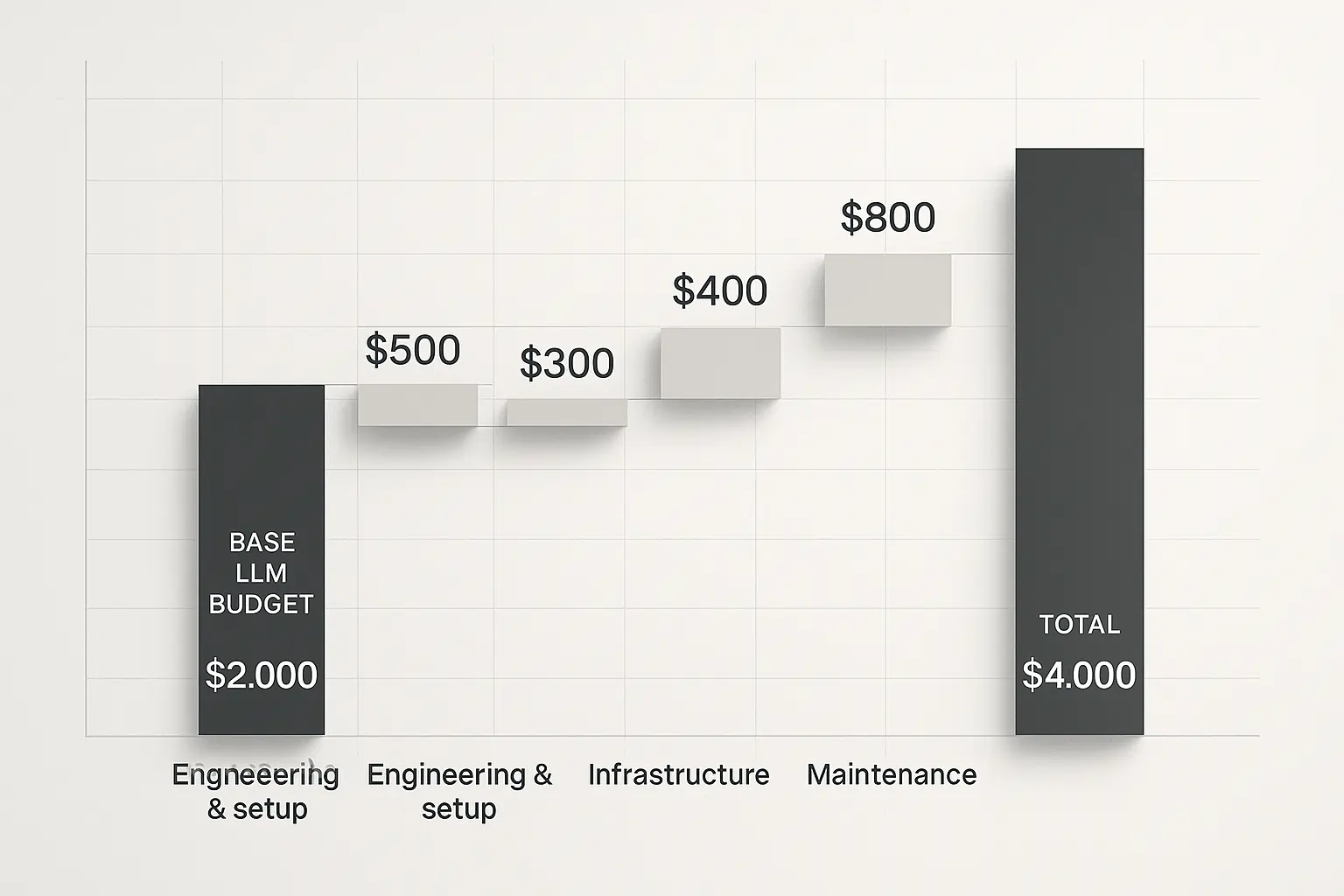
Engineering & Setup Costs
Your setup steps aren’t just configuration tweaks. Production LLM integration requires:
- Custom API wrappers for error handling and rate limiting
- Prompt engineering across multiple use cases and edge conditions
- Fine-tuning processes that demand specialized ML expertise
- Testing frameworks for model performance and accuracy validation
Budget reality check: Plan $40,000-$100,000 for engineering setup, depending on complexity. A mid-sized e-commerce platform I worked with burned $67,000 just getting their customer service LLM production-ready.
Token Usage & Processing Costs
Token consumption follows Murphy’s Law: it’ll cost more than you think. (OpenAI Documentation)
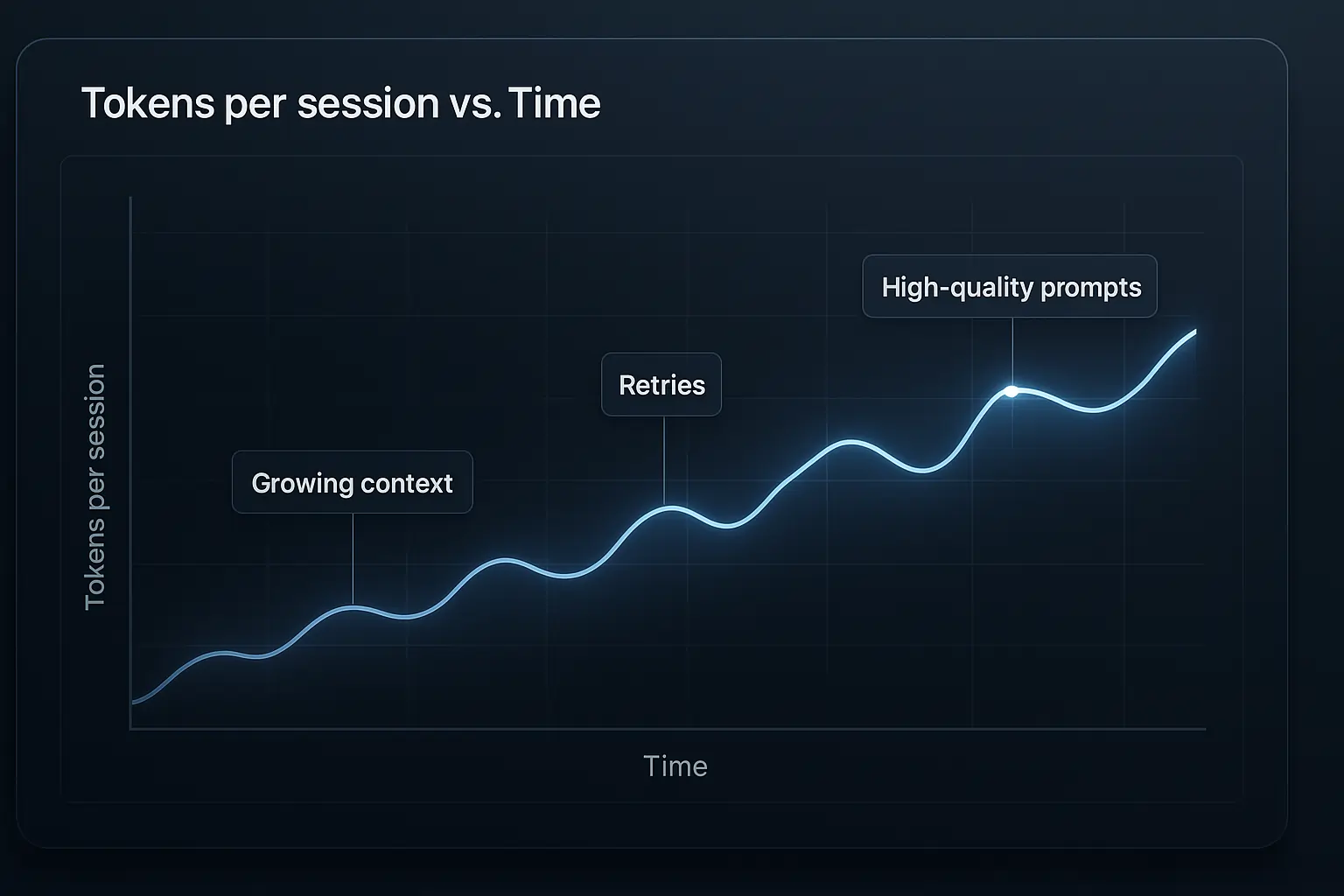
Specific data shows that production applications typically consume 300-500% more tokens than development estimates due to:
- Conversation context that grows with session length
- Error recovery mechanisms that retry failed requests
- High-quality outputs requiring longer, more detailed prompts
- Real-time processing that can’t optimize for batch efficiency
Infrastructure Costs
Compute resources scale non-linearly with user adoption. When that viral TikTok sends 10,000 users to your AI-powered app simultaneously, your AWS bill doesn’t just double, it explodes.(AWS Pricing)
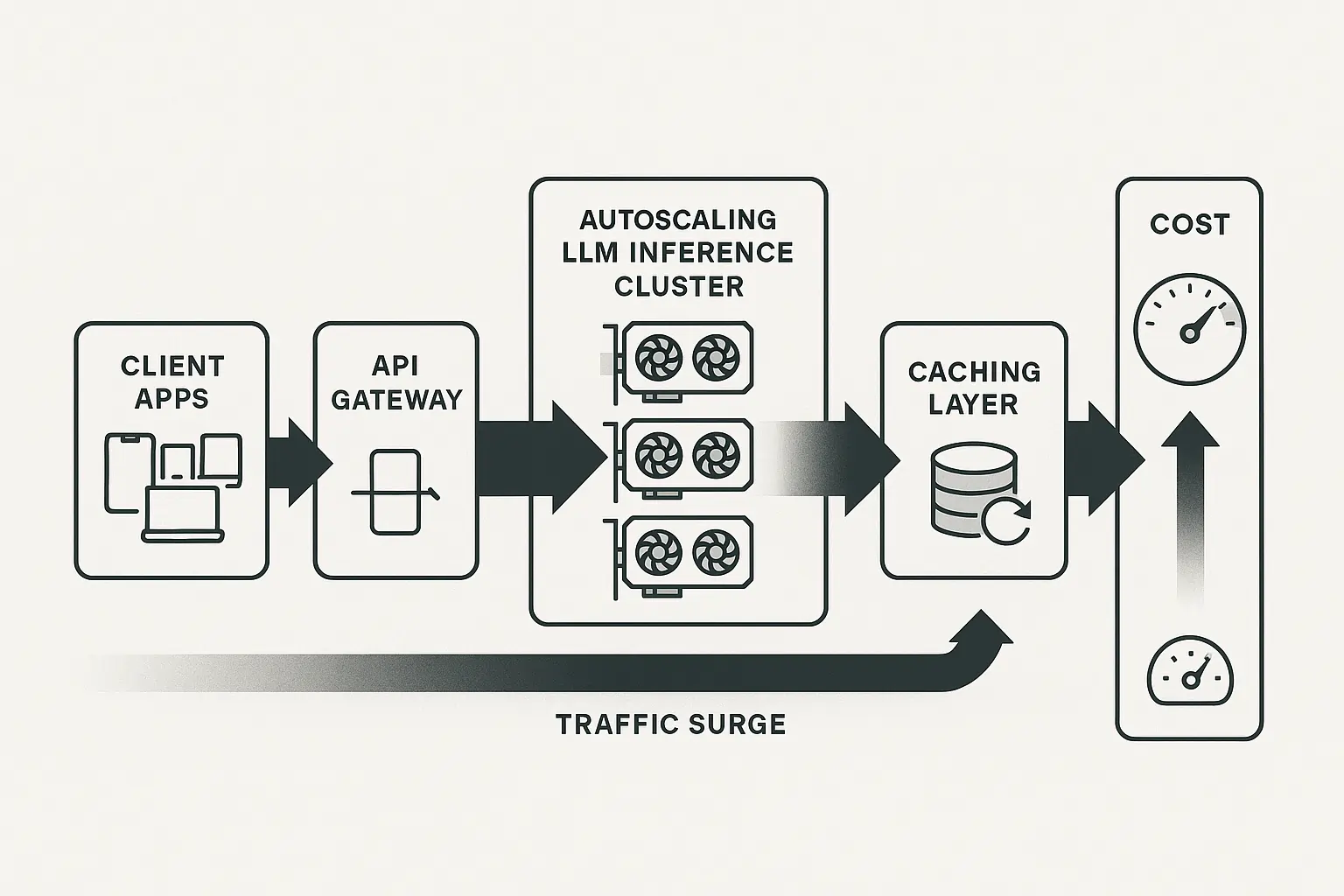
Critical Infrastructure Components:
- Load balancing for API rate limit management
- Caching layers to reduce redundant model calls
- Monitoring systems for performance and cost tracking
- Backup systems for model availability and failover
Long-Term Maintenance & Updates
The gift that keeps on taking from your budget. Long-term costs include:
- Model versioning and migration testing
- Security patches and compliance updates
- Performance optimization as usage patterns evolve
- AI systems monitoring and anomaly detection
How to Estimate and Manage LLM Integration Costs Efficiently?
Accurate cost estimation requires analyzing token patterns, infrastructure scaling curves, engineering time allocation, and maintenance overhead using production data rather than theoretical calculations. (McKinsey AI Reports)
Token Usage Analysis: Track your number of tokens across different user scenarios. Build a token calculator based on actual prompt lengths, not vendor examples—factor in conversation context, error handling, and retry mechanisms.
Model Selection Strategy: Compatibility with your existing systems affects the total cost of ownership. Consider:
- Cost-effective alternatives for simple tasks
- Model costs versus performance trade-offs
- Pricing model flexibility for varying workloads
Step 3: Design infrastructure for scalability from day one. Cloud costs compound quickly when you’re reactive rather than proactive about capacity planning.
Step 4: Maintenance Budget Allocation Reserve 20-30% of your initial integration budget annually for maintenance, updates, and optimization.
Top Strategies to Reduce LLM Integration Costs
Innovative organizations reduce LLM costs through dynamic model routing, hybrid architectures, efficient prompt engineering, strategic model selection, and intelligent caching, cutting expenses by 40-70% while maintaining performance.

Dynamic Model Routing
Route simple queries to cheaper models like GPT-3.5 while reserving GPT-4 for complex tasks. One client reduced costs by 45% using this approach.
Hybrid Architectures
Combine open-source models for basic tasks with premium models for specialized requirements. Think of it as having both a Toyota for daily driving and a Ferrari for special occasions.
Efficient Token Management
Reduce costs through:
- Shorter, more focused prompts
- Context trimming for long conversations
- Batch processing, where possible
- Smart caching for repeated queries
Open-Source Model Integration
Consider models like LLaMA for specific use cases. While setup complexity increases, licensing costs disappear entirely. (Forbes AI Articles)
Cloud vs. On-Premises Optimization
Balance cloud flexibility with on-premises control based on usage patterns and operational costs.
Real-World Examples of LLM Integration Costs
A fintech startup reduced its monthly LLM costs from $23,000 to $8,500 through prompt optimization and hybrid model routing (Towards Data Science on AI Costs). At the same time, a healthcare platform cut token usage by 60% using intelligent caching strategies. (MIT Technology Review AI)
Case Study 1: E-commerce Platform
Initial budget: $12,000/month.h Actual costs after optimization: $7,200/monThe keyy savings: Dynamic routing (30% reduction), prompt engineering (25% reduction)
Case Study 2: Content Marketing Agency
Challenge: Unpredictable token usage spik.es Solution: Implemented request batching and context management.ent Result: 40% cost reduction with improved response consistency
The healthcare platform’s success came from recognizing that medical terminology queries are often repeated. Their intelligent caching system now handles 60% of requests without model calls, dramatically reducing real-time costs.
Managing Hidden Costs for Long-Term Success
Successful LLM integration requires treating hidden costs as first-class planning considerations, implementing monitoring systems from day one, and maintaining flexibility to adapt pricing models as technology evolves.
The brutal truth? LLM integration costs will surprise you. But forewarned is forearmed. Thoughtful planning, realistic budgeting, and continuous optimization transform those shocking bills into manageable, predictable expenses.
Start with pilot projects to gather real usage data. Build monitoring into your architecture from the beginning. And remember the goal isn’t to minimize costs at all costs, but to maximize value while controlling expenses.
The companies winning with LLM integration aren’t necessarily spending less; they’re spending smarter, with complete visibility into where every dollar goes and why it matters.
Key Takeaway: Budget for reality, not marketing materials. Your future self will thank you when those hidden costs become visible line items instead of budget-busting surprises.

{kind=link}