
LLM integration connects AI language models to business systems through APIs, enabling automated text generation, intelligent customer support, and scalable decision-making.
By 2025, GenAI usage will be mainstream across organizations, and its integration will have shifted from pilot to a baseline capability.
What is LLM Integration in 2025?
LLM integration connects large language models, such as ChatGPT (GPT -4 family), Claude, Gemini, DeepSeek, or open-source options (e.g., Llama), to your applications via API calls, enabling automated text generation and intelligent responses using your proprietary data.
Modern implementations combine APIs with vector databases and fine-tuning to create context-aware systems that understand your business domain and generate responses that feel natural and accurate.
The LLM setup process has become streamlined with better tooling and standardized approaches.
LangChain + Pinecone for customer support that answers questions using your knowledge base with proper citations.
The widespread adoption of AI coding and integration tools by developers is now common, with daily use among professional teams expected to be prevalent by 2025. (2025 Developer Survey)
LLM Integration Definition
LLM integration is the process of connecting large language models to business applications through:
• API endpoints that handle text generation requests and manage rate limit constraints
• Vector databases that store and retrieve contextual information for enhanced accuracy
• Error handling systems that manage failures and ensure consistent user satisfaction
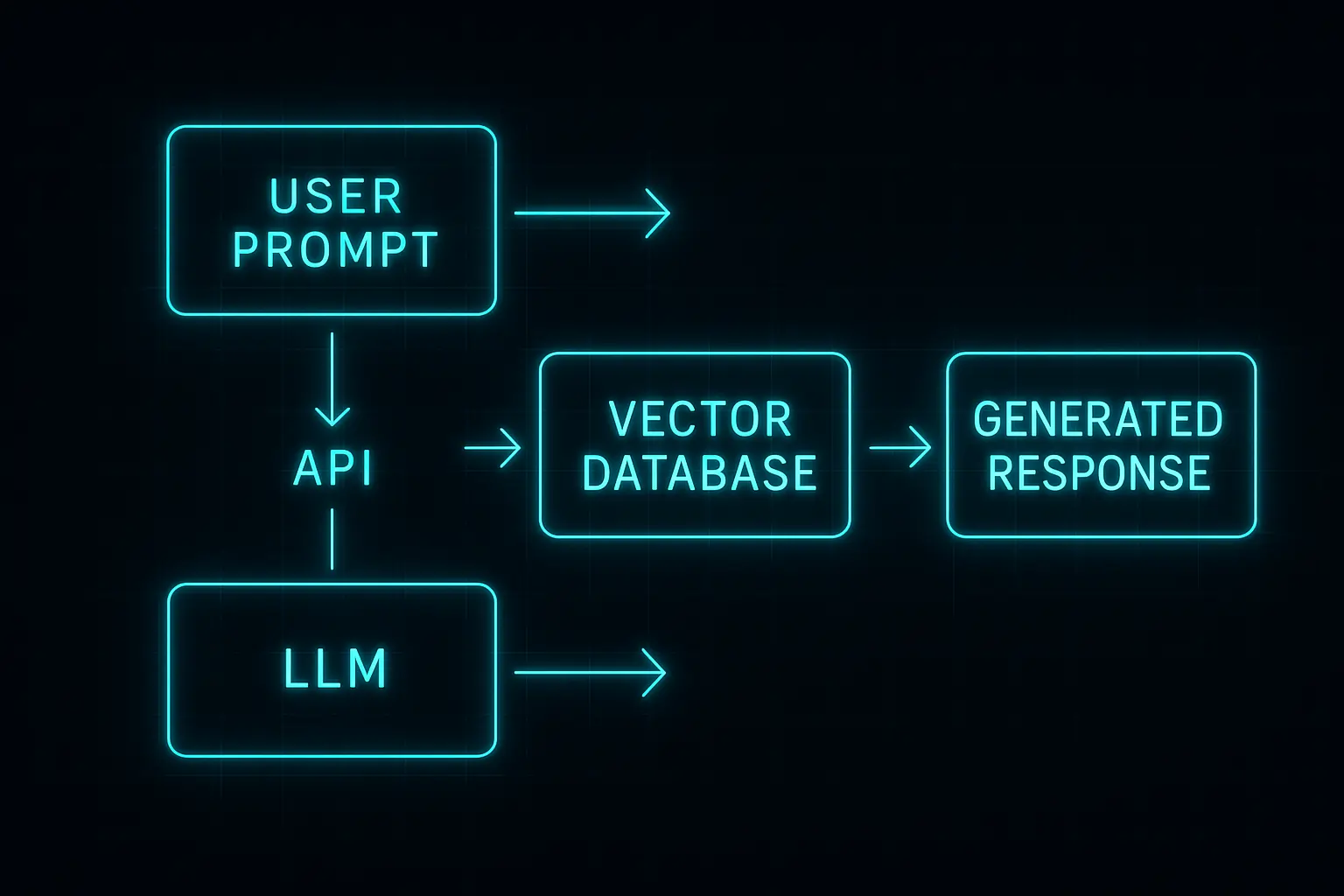
5-Step Basic Integration Process
- Choose your model (OpenAI, Anthropic, or open source options)
- Set up API authentication and configure rate-limiting policies
- Design prompts for your specific text generation use cases
- Implement error handling and retry mechanisms for robust customer service
- Monitor performance and optimize response times across all API calls
How Does LLM Integration Actually Work From API to Response?
LLM integration processes user input through API calls to language models, which generate responses using machine learning algorithms trained on vast text datasets, returning formatted outputs in milliseconds.
The technical flow involves request formatting, model inference, response parsing, and context management. Production systems incorporate caching, monitoring, and multi-model routing to enhance reliability and performance. Understanding model compatibility ensures smooth operations across different LLM providers.
A customer service integration receives questions, checks the ve and performancector database for relevant context, sends enriched prompts to the model, and returns personalized answers.
Improve perceived speed with token streaming, and enhance reliability by utilizing retry with exponential backoff, circuit breakers, and fallback routing across providers.
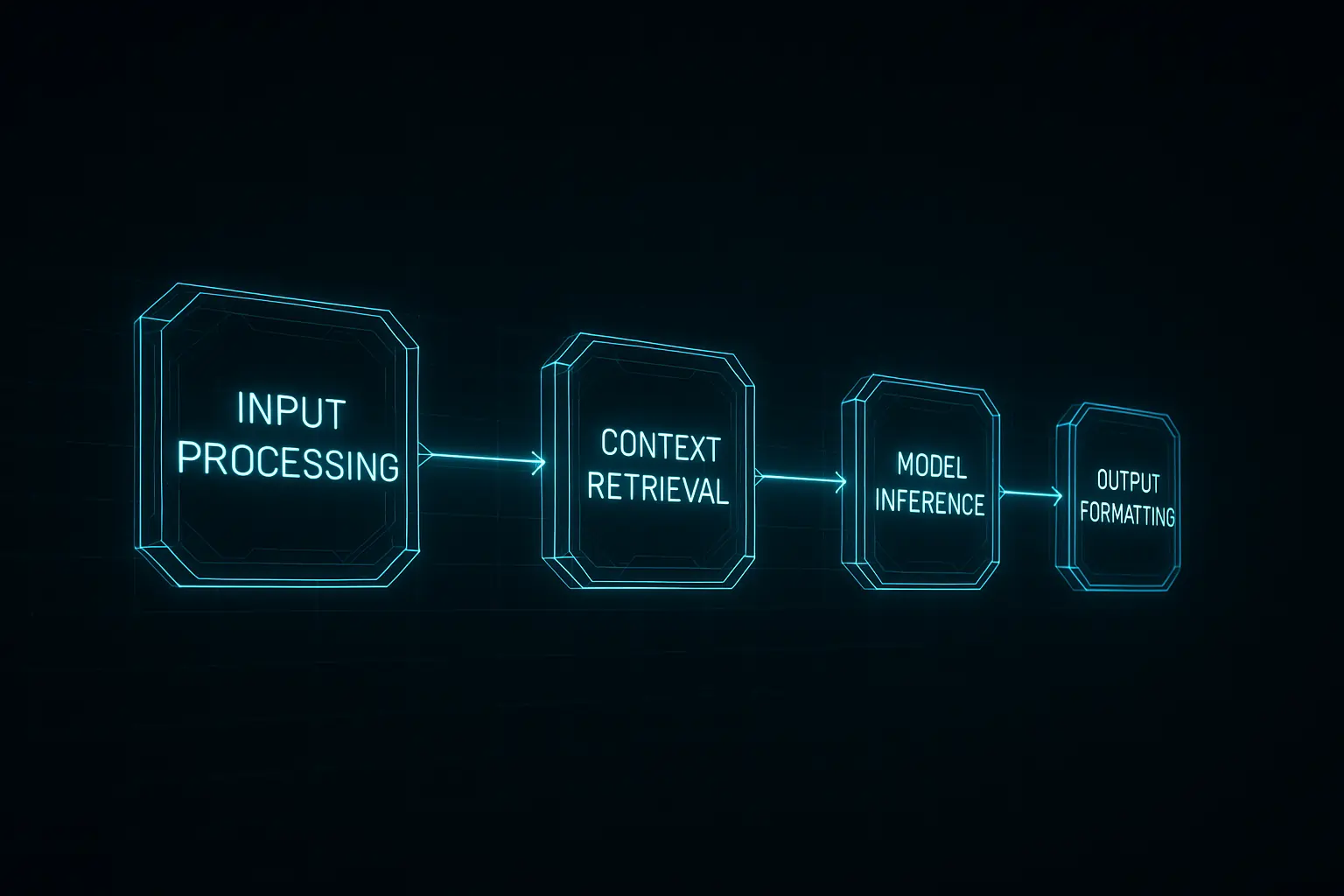
Core Integration Architecture
• Input Processing: User queries parsed and formatted for optimal text generation
• Context Retrieval: Vector database searches for relevant information using embeddings
• Model Inference: LLM generates contextually appropriate responses with proper error handling
• Output Formatting: Results structured for end-user consumption in customer support workflows
Which Use Cases Deliver ROI Right Now?
Customer support automation, content generation, and language translation deliver immediate ROI, with companies seeing 40-67% efficiency gains and 300% return on investment within 12 months.
High-value applications focus on automating repetitive tasks that require language understanding and comprehension. Customer service leads adoption because the impact is immediately measurable through resolution times and user satisfaction scores. The proper integration tools can accelerate deployment and maximize returns.
A consumer SaaS support team automated 60–80% of routine inquiries with RAG and agent-assist, while preserving human oversight for edge cases.
Enterprise AI and GenAI spending expanded materially in 2025 as budgets shifted from pilots to production. (Zendesk AI Customer Experience Report 2025)
Top 5 High-ROI Applications
- Customer Support Automation – 60% cost reduction through intelligent response generation
- Content Generation – 300% productivity increase with fine-tuning for brand voice
- Language Translation – 85% faster processing across multiple languages
- Data Analysis – 50% faster insights using large language models
- Code Generation – 40% development acceleration with specialized LLMs
Can RAG Work with Any LLM?
Yes, Retrieval Augmented Generation (RAG) works with most modern language models through standardized embedding APIs, although performance varies based on the context window size and training methodology.
Model compatibility depends on the model’s ability to effectively process external context. Larger context windows and instruction-following capabilities significantly improve RAG performance. The RAG integration process requires careful consideration of each model’s strengths and weaknesses.
Companies successfully implement RAG with GPT-4 (128k context), Claude-3.5 (200k context), and Llama-3 (8k context) using identical vector database architectures and weaknesses.
RAG has become a standard integration pattern for grounding LLM outputs with private data; most production stacks include embeddings, along with a vector database.
LLM Compatibility Matrix
| Provider | Context Window | RAG Performance | Best Use Case | See Pricing |
|---|---|---|---|---|
| OpenAI (GPT-4o / 4o mini) | up to 128K tokens (model-dependent) | Generalist + tool use | Content, agent tools | OpenAI Pricing |
| Anthropic (Claude Sonnet 4) | up to 1M tokens (beta/tiered) | Long-context analysis; safety | Research, policy review | Anthropic Pricing |
| Google (Gemini 2.5) | 1M tokens | Long-context + multimodal | Document analysis, real-time grounding | Google AI Pricing |
| Azure OpenAI | 128k tokens | Excellent | Enterprise compliance needs | Azure Pricing |
| Open-source (Llama family) | varies by model card (extensions available) | Cost/privacy control | Internal apps | Model cards |
How Do I Handle Rate Limits, Latency, and Error Handling?
Implement exponential backoff for rate limit errors, utilize response caching for common queries, and design failover mechanisms that automatically switch between multiple LLM providers.
Production systems require robust error handling because API calls can fail, models can be temporarily unavailable, and usage can spike unpredictably. Innovative architectures are planned for these scenarios from day one. Proper integration tools provide monitoring and automated responses to these challenges.
A three-tier fallback primary LLM → backup provider → cached responses—keeps customer-facing services responsive during spikes or provider outages.
In 2024, 78% of enterprise LLM integrations experienced disruptions from multiple vendors, driving the adoption of Multivendor architectures in 2025 (IDC Enterprise AI Infrastructure Report 2025).
Essential Error Handling Patterns
• Rate Limiting: Exponential backoff with jitter to manage API calls effectively
• Timeout Management: 30-second maximum with streaming for optimal response times
• Circuit Breakers: Automatic failover after three consecutive failures in any LLM
• Request Queuing: Buffer non-urgent requests during peak usage to maintain user satisfaction
What Does Secure, Compliant LLM Integration Look Like in 2025?
Compliant LLM integration requires data encryption, audit trails, access controls, and adherence to regulations such as the EU AI Act, which mandates transparency for general-purpose AI systems starting in August 2025.
Compliance frameworks now include specific requirements for AI systems. The EU AI Act classifies general-purpose LLMs as high-risk, requiring documentation of training data, model capabilities, and risk mitigation strategies. Machine learning systems must demonstrate responsible AI practices.
Healthcare organisations use on-premises deployment with encrypted vector databases to maintain HIPAA compliance while leveraging LLM capabilities for patient support.
From 2 August 2025, GPAI providers must meet transparency and documentation requirements (training summary, technical documents, and incident reporting).
Systemic-risk GPAI has additional obligations (risk assessments, adversarial testing). Integrators should log retrieval sources, apply PII redaction, and maintain audit trails.
Compliance Checklist
• Data Privacy: End-to-end encryption and data residency controls for all API calls
• Access Management: Role-based permissions and authentication for LLM API integrations
• Audit Trails: Complete logging of all interactions involving text generation and customer service
• Risk Assessment: Documented evaluation of model outputs and biases in learning model behavior
How Much Will LLM Integration Cost and How Should I Budget?
Initial implementation costs range from $5,000 to $50,000, depending on complexity, with ongoing operational expenses of 10-20% annually. However, ROI typically reaches 300% within 12 months through efficiency gains.
Cost factors include API usage, vector database hosting, development time, and ongoing maintenance. Smart budgeting focuses on usage patterns rather than maximum capacity to control costs. Fine-tuning requirements can significantly impact overall expenses.
Mid-size companies typically spend $800-$3,000 monthly on production LLM integrations serving 10,000-50,000 users with comprehensive customer support automation.
Average enterprise LLM integration budgets increased to $240,000 in 2025, with 67% citing faster time-to-market as the primary ROI driver (McKinsey Enterprise AI Spending Report 2025). Microsoft Azure AI Cost Calculator
Cost Structure Breakdown
• Development: 40-50% of the initial budget for LLM setup and customization
• API Usage: 25-35% of ongoing costs based on text generation volume
• Infrastructure: 15-25% for vector database hosting and response times optimization
• Maintenance: 10-15% for monitoring, updates, and error handling improvements
What’s the Best Integration Roadmap for the First 180 Days?
Start with basic API integration and simple use cases. Add vector database and RAG capabilities by month 3, and then implement advanced features, such as agent-based workflows and real-time processing, by month 6.
Successful real-time implementations follow a phased approach that builds complexity gradually while maintaining system stability and team learning velocity. This approach ensures proper user satisfaction throughout the deployment process.
Teams using a phased rollout (prototype → RAG → real-time) reach production faster and maintain quality as complexity increases.
Companies using phased implementation achieve 43% faster time-to-production compared to big-bang approaches (Gartner Enterprise AI Implementation Study 2025).
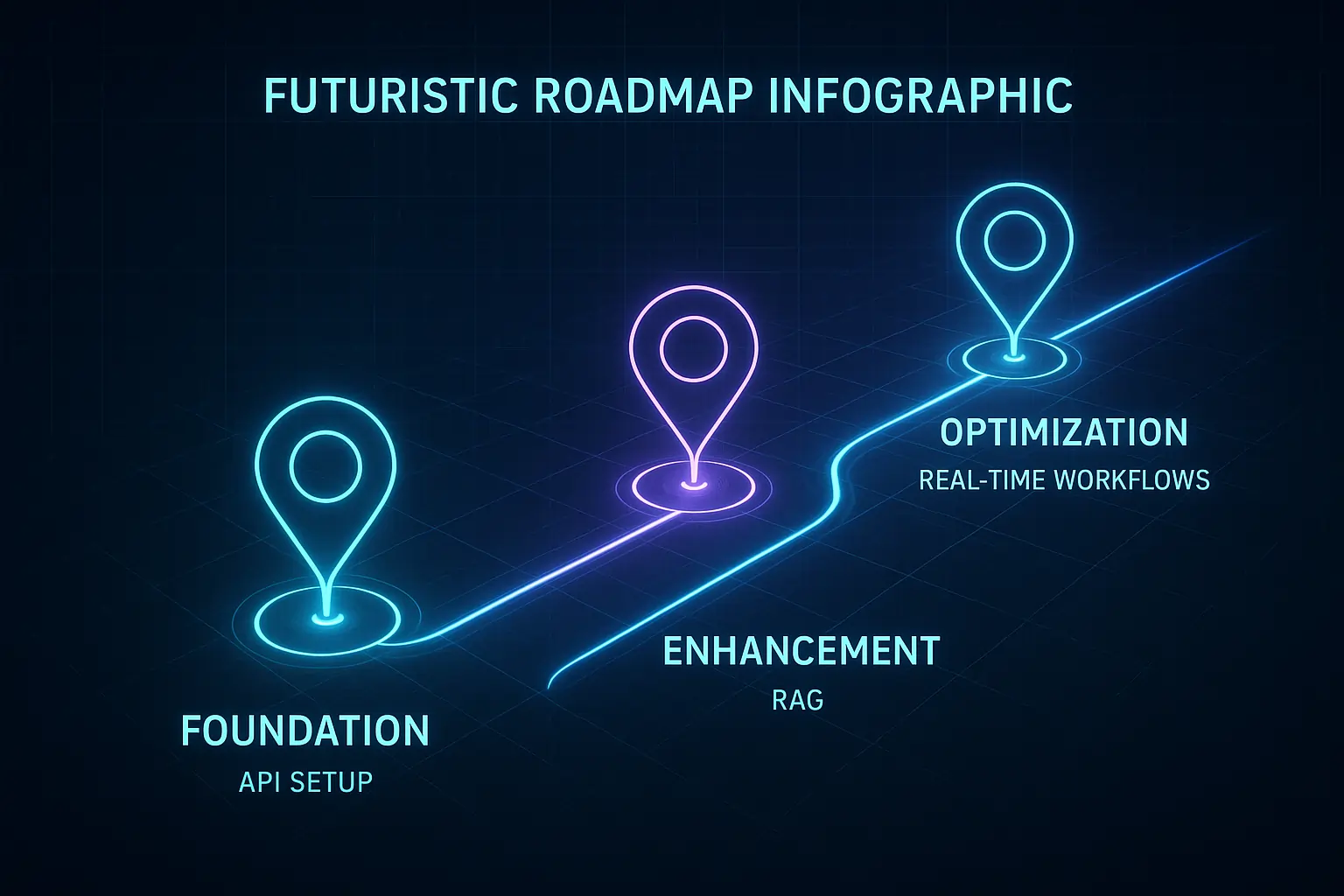
3-Phase Implementation Roadmap
| Phase | Timeline | Focus | Key Deliverables |
|---|---|---|---|
| Foundation | Months 1-2 | Basic API integration and LLM setup | Working prototype, team training, error handling |
| Enhancement | Months 3-4 | RAG integration and optimization | Production deployment, response times tuning |
| Optimization | Months 5-6 | Advanced features and real-time processing | Agentic workflows, monitoring dashboard |
Which Vendors and Tools Are Suitable for Which Scenarios?
Choose OpenAI for general-purpose applications, Anthropic for analysis-intensive tasks, and Google Gemini for long-context processing. These options are Suitable for open-source models in cost-sensitive or privacy-critical deployments.
Vendor selection depends on your specific requirements for context length, safety features, cost constraints, and deployment preferences. Most enterprises use multiple providers and various vendors; proper integration tools help manage complex vendor environments. Financial services typically utilize Azure OpenAI for regulatory compliance, combining it with open-source models for internal tools and customer service applications.
Multivendor architectures are increasingly popular for mitigating rate limits, outages, and cost variance across providers. (Hugging Face Model Hub)
Vendor Selection Matrix
| Provider | Strength | Best Use Case | Key Features | See Pricing |
|---|---|---|---|---|
| OpenAI | Versatility/coding | Content generation, tool use | Advanced reasoning, large language models | OpenAI Pricing |
| Anthropic | Safety/analysis | Research, policy review | Constitutional AI, safety focus | Anthropic Pricing |
| Google Gemini | Long-context/multimodal | Document analysis, real-time data | 2M token context, multimodal | Google AI Pricing |
| Azure OpenAI | Enterprise controls | Regulated industries | Enterprise compliance, security | Azure Pricing |
| Open Source | Cost factors/privacy | Internal applications | Complete control, no rate limit | Infrastructure costs only |
What Trends Matter Most for 2025 and Beyond?
Real-time streaming responses, agentic workflows that chain multiple LLM calls, extended context windows up to 2 million tokens, and integrated multimodal capabilities are reshaping LLM integration architectures.
These trends enable more sophisticated applications that can handle complex business processes autonomously while maintaining human-like interaction quality.
Machine learning advances continue pushing the boundaries of what’s possible with text generation and customer support automation.
Salesforce’s new agentic workflows automatically research prospects, draft personalized outreach, and schedule follow-ups across multiple communication channels using advanced LLM API integrations.
Investment in agentic AI workflows reached $12.4 billion in 2025, with 156% year-over-year growth in enterprise adoption (Anthropic Industry Trends Report 2025).
Top 5 Integration Trends for 2025
- Real-Time Streaming: Sub-second response initiation with progressive output delivery
- Agentic Workflows: Multi-step autonomous task execution using a type of LLM specialization
- Extended Context: Processing entire documents without summarization using large language models
- Multimodal Integration: Text, image, and audio processing in single workflows for enhanced user satisfaction
- Edge Deployment: Local processing for latency-sensitive customer service applications
Frequently Asked Questions (2025)
1. What is LLM integration?
It’s the process of connecting large language models (LLMs) to your business systems through APIs, allowing them to generate context-aware responses.
2. How do I start with LLM API integrations?
Pick a provider (e.g., OpenAI, Anthropic), set up authentication, run simple test prompts, then expand with RAG and monitoring.
3. What is RAG, and why use a vector database?
RAG retrieves context from a vector database before the model generates a response, reducing hallucinations and improving accuracy.
4. How do I handle rate limits and errors?
Use exponential backoff for retries, cache common queries, and add failover routing across multiple LLM providers.
5. How much does LLM integration cost?
Budgets vary, but expect to invest $5,000–$50,000 for setup and 10–20% annual upkeep; ROI often reaches 300% within 12 months.
Quick Start: LLM Integration Resources (2025)
Internal Guides
LLM setup → Foundation
RAG integration → Accuracy
Model compatibility → Vendors
Integration tools → Efficiency
Compliance → Regulations
Real-time → Latency
Cost factors → Budget
External References
OpenAI Guide
Anthropic Safety
Google Cloud AI
Azure AI Services
Next Step
➡️ New? Start with the LLM setup
➡️ Scaling? Get an architecture review
➡️ All-in? Download the 2025 LLM Integration Checklist (Premium Edition)

{kind=link}